
Despite growing investments in analytics, teams often struggle to turn raw data into actionable insights. Reports are delayed, definitions vary across tools, and campaign performance is harder to compare than ever. The real issue isn’t the lack of data; it’s the lack of a consistent and reliable process to unify and prepare that data for informed decision-making.
ETL (Extract, Transform, Load) sits at the core of any effective business intelligence system. This article breaks down why ETL matters, how it improves reporting and analysis, and what tools and methods can help streamline your data workflows.
Quick answer
ETL for business intelligence is a foundational process that extracts data from multiple sources, transforms it by cleaning and standardizing metrics, and loads it into a central data warehouse. This enables marketing teams to consolidate fragmented data sets, improve reporting accuracy, reduce manual work, and make faster data-driven decisions based on consistent, analysis-ready information.
What Is the ETL Process and How Does It Work?
ETL, short for Extract, Transform, Load, is a foundational component of any business intelligence (BI) strategy. It enables organizations to collect data from multiple systems, standardize it for analysis, and centralize it in a data warehouse or analytics environment.
Without ETL, marketing teams are left juggling fragmented data sets that are difficult to analyze and trust.
The ETL process includes three crucial steps:
- Extraction is the first step, which involves collecting raw data from disparate sources. In the context of marketing, these sources often include advertising platforms, CRMs, analytics tools, and internal databases. This stage requires robust connectors to ensure data is pulled accurately and regularly without losing granularity or metadata.
- Transformation is where data becomes analysis-ready. Raw data is rarely useful as-is; it needs to be cleaned, deduplicated, aligned across naming conventions, and normalized. For marketing teams, this includes standardizing campaign metrics like CPC or ROI, reconciling platform taxonomies, and aligning attribution models. The transformation step ensures consistency and enables meaningful comparison across channels.
- Loading involves moving the transformed data into a central repository, typically a data warehouse. Once loaded, this data becomes accessible for reporting, visualization, and advanced analytics. In marketing operations, the centralized data supports everything from real-time dashboards to machine learning models and campaign optimizations.
A well-orchestrated ETL process reduces manual data work, ensures data quality, and provides a reliable foundation for business intelligence.
Why Is ETL Important in Business Intelligence?
In the context of marketing analytics, where data comes from dozens of platforms, ETL is what filters out noise and inconsistencies to produce meaningful insights.
The benefits go beyond data hygiene, as they directly impact reporting accuracy, operational efficiency, and the ability to adapt strategies in real-time.
1. Enhanced analytics and decision-making
A primary benefit of ETL is improved analytics, which leads to better and faster decisions. By consolidating data from various sources into one consistent view, ETL ensures that analyses are based on complete and uniform datasets.
In practical terms, this means less time spent manually reconciling discrepancies in spreadsheets and more time extracting insights. Marketing teams often find that with ETL automation in place, they spend less time fixing errors and more time using the data to make informed, data-driven decisions.
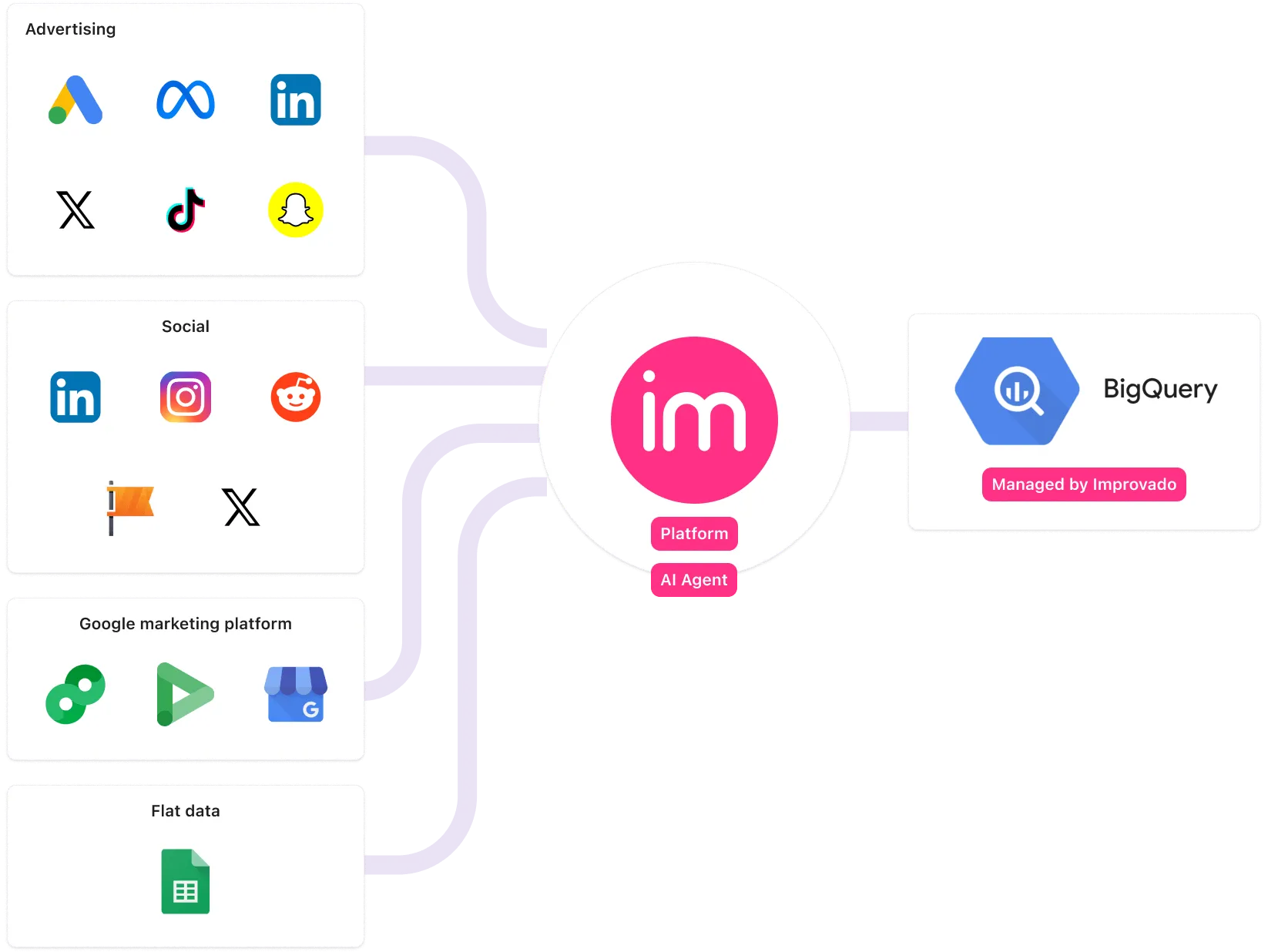
ASUS needed a centralized platform to consolidate global marketing data and deliver comprehensive dashboards and reports for stakeholders.
Improvado, a marketing-focused enterprise ETL, seamlessly integrated all of ASUS’s marketing data into a managed BigQuery instance. With a reliable data pipeline in place, ASUS achieved seamless data flow between deployed and in-house solutions, streamlining operational efficiency and the development of marketing strategies.
"Improvado helped us gain full control over our marketing data globally. Previously, we couldn't get reports from different locations on time and in the same format, so it took days to standardize them. Today, we can finally build any report we want in minutes due to the vast number of data connectors and rich granularity provided by Improvado."

2. Real-time or near real-time data integration
Modern ETL continually updates the data repository with fresh information as soon as it becomes available.
Embracing real-time integration enables businesses to work with the most current data, allowing for agile decision-making and a faster response to changing conditions.
3. Improved data warehousing
ETL and data warehousing go hand-in-hand.
A data warehouse is a centralized repository for an organization’s structured data, and a well-executed ETL process greatly enhances the warehouse’s value.
Effective ETL improves data warehousing in several ways:
- ETL serves as the gatekeeper for data entering a warehouse. It means only relevant, cleansed data is stored, which optimizes storage and query performance.
- ETL provides a consolidated data view that simplifies reporting: rather than juggling multiple data exports, users query one repository where everything is already joined and standardized.
- A solid ETL framework boosts scalability for the warehouse. As data volumes explode, ETL processes can be designed to handle large-scale loads and incremental updates so the warehouse keeps up without bottlenecks.
Booyah Advertising needed to streamline reporting across dozens of clients, each using 15-20 data sources, with larger clients requiring double that number.
By adopting Improvado, Booyah automated data ingestion and transformation, creating clean, unified flows that directly integrated with Google BigQuery.
This shift allowed analysts to work from a centralized source of truth, accelerating report delivery, reducing data QA cycles, and supporting scalable growth.
“Once the data's flowing and our recipes are good to go—it's just set it and forget it. We never have issues with data timing out or not populating in GBQ. We only go into the platform now to handle a backend refresh if naming conventions change or something. That's it.”

4. Reduced manual work and reporting overhead
One of the most immediate benefits of ETL in business intelligence is the automation of routine data collection, cleansing, and transformation tasks.
A well-designed ETL pipeline eliminates this overhead by standardizing inputs before they reach the data warehouse or reporting layer. This includes automated mapping of metrics and dimensions, applying naming conventions, resolving schema mismatches, and filtering out irrelevant or low-quality records.
The result is not only time saved but also a reduction in human error and QA cycles. Analysts can shift their focus from data preparation to insight generation, and reporting teams can operate at scale.
Before Improvado, preparing reports at Signal Theory was a labor-intensive process, often taking four hours or more per report. Switching to Improvado reduced that time by over 80%, making reporting significantly more efficient and far less stressful.
Automation allows a single analyst at Signal Theory to manage data for 10 global clients at once.
"Reports that used to take hours now only take about 30 minutes. We're reporting for significantly more clients, even though it is only being handled by a single person. That's been huge for us.”

What Tools and Technologies Power ETL in Business Intelligence?
Implementing ETL for business intelligence typically involves specialized tools or platforms.
Over the years, a wide variety of ETL tools have emerged, each suited to different needs. It’s important to choose the right technology, especially for marketing analytics, because not all ETL tools are equal in handling marketing data.
Below is an overview of major categories of ETL tools and technologies:
- Open-source ETLs: These are community-driven platforms or libraries that offer flexible, customizable data integration without licensing costs. Open-source ETL solutions, such as Talend Open Studio, Apache NiFi, or Airbyte, are favored by tech-savvy teams seeking cost-effective options and the ability to customize the code. They provide a wide range of features and connectors, though they may require more technical expertise to set up.
- Cloud-based ETL services: Many organizations now leverage cloud ETL platforms such as AWS Glue, Microsoft Azure Data Factory, Google Cloud Data Fusion, or BigQuery Data Transfer Service. These managed services utilize cloud infrastructure to handle large-scale data integration tasks. Cloud-based ETL tools offer scalability, cost efficiency, and easy integration with other cloud services. For a marketing team dealing with spikes in data (for example, e-commerce transactions during a holiday sale), a cloud ETL service can automatically scale resources and reliably process the data on schedule.
- Real-time or streaming ETL tools: Technologies like Apache Kafka, Apache Flink, or purpose-built tools like Striim enable continuous data flow rather than batch jobs. Streaming ETLs are useful when you need dashboards updated by the minute or instant alerting on specific events (for example, monitoring social media mentions or ad click streams in real-time). Many traditional ETL vendors have also added support for micro-batches or streaming, allowing data to be ingested more frequently than the classic daily load.
- Self-service ETL and no-code tools: For non-technical users or small teams without dedicated data engineers, self-service ETL tools provide a more user-friendly approach. These tools offer drag-and-drop interfaces and require minimal coding. Such an approach democratizes data integration and reduces reliance on IT for every new report. The trade-off is that these tools may be less flexible for very complex transformations, but they greatly speed up development for common tasks.
- Marketing-specific ETL solutions: Recognizing the unique needs of marketing analytics, several tools focus solely on integrating marketing data. Services like Improvado, Funnel, TapClicks, and others come with pre-built connectors for dozens of ad networks, social platforms, and marketing software. They understand marketing metrics and often allow transformations specific to marketing use cases. Marketing ETL tools are typically cloud-based and offer automation to update dashboards on a daily or even hourly basis.
The good news is that the ETL tool ecosystem is rich in 2026. There are dozens of proven solutions that cover almost any scenario. The key is to choose a tool that fits your team’s skill set and business requirements.
Here’s a quick recap of the pros and cons of different ETL solutions.
| ETL type | Pros | Cons | Best use case |
|---|---|---|---|
| Open-source | Free to use; highly customizable; large developer community | Requires engineering resources; no vendor support | Teams with strong in-house data engineering that need full control |
| Cloud-based | Scalable; minimal setup; managed infrastructure | Can become expensive at scale; less customizable | Organizations that prioritize scalability and ease of deployment |
| Real-time | Low-latency updates; ideal for time-sensitive metrics | More complex setup; can be costly to maintain | Campaign pacing, real-time alerts, and operational dashboards |
| Self-service | No-code interfaces; fast setup; minimal IT dependency | Limited flexibility; not ideal for complex transformations | Marketing teams needing quick access to standardized data without engineers |
| Marketing-specific | Prebuilt connectors and models; tailored for marketing KPIs | Less adaptable for non-marketing data | Agencies and brands managing cross-channel marketing performance |
What Are the Best Practices for ETL in BI?
Deploying ETL is not just about tools and pipelines, following best practices is crucial to ensure the process is efficient, reliable, and delivering value.
Marketing organizations, in particular, should adhere to certain guidelines so that their data integration supports agile decision-making without a lot of firefighting or rework.
1. Ensure data quality at the source and throughout
A classic saying in data management is garbage in, garbage out.
If the input data is full of errors or inconsistent, the outputs, whether it is reports, models, or insights, will be flawed. Thus, prioritize data quality at every step of the ETL process.
- This involves cleaning data early, removing duplicates, fixing obvious errors, standardizing formats, and validating it continuously.
- Using automated data quality checks can catch missing or out-of-range values before they flow downstream.
- For marketing teams, this may involve verifying that campaign names adhere to a standard format or that currency fields contain valid numbers.
2. Minimize and optimize data inputs
Efficient ETL means not processing more data than necessary.
It’s best practice to filter out unnecessary or redundant data as early as possible in the pipeline. For example, if certain columns or records are not needed for analysis, exclude them during extraction rather than carrying them through the transform and then discarding them.
Similarly, if you have old data that will never be used, consider archiving it instead of including it in every load. By trimming the input, you make ETL jobs faster and reduce clutter in the target system.
Many teams also adopt incremental loading, which involves importing only new or changed data since the last run, rather than performing full reloads each time. For instance, rather than re-pulling all historical campaign data daily, you would just pull yesterday’s new data.
3. Automate the data pipeline and schedule the processes
Whenever possible, automate your ETL workflows end-to-end.
Manual intervention not only consumes staff time but also introduces the risk of human error. The goal should be a hands-free daily or hourly pipeline that reliably runs on a schedule or trigger.
Modern ETL tools allow scheduling jobs, detecting changes for event-driven loads, and even auto-scaling resources. For a marketing analytics team, automation might mean scheduling data refreshes overnight so that each morning, the dashboards are updated with the latest metrics without anyone having to pull data manually.
4. Monitor, error-handle, and validate
No ETL process is perfect. Things will occasionally fail or produce unexpected results. Establishing strong error handling and monitoring is therefore essential.
- This means setting up alerts and notifications so that if a scheduled job fails or data looks anomalous, the right people are notified immediately.
- Logging is also important: the ETL system should log what it did and any issues encountered, including row counts and error rows, for auditability and debugging purposes.
- Regular data validation is also a must. Verify that the number of records loaded matches expectations, or that key metrics in the warehouse align with the source reports within a specified tolerance. For instance, a marketing team might verify that total ad spend in the data warehouse for the week is within a small percentage of the sum shown in the ad platform UIs, as a sanity check.
What Are the Future Trends in BI ETL?
The integration of AI into ETL processes, new challenges, and evolving data policies in the coming years will bring significant changes to how marketing data pipelines are built and managed.
- Convergence of ETL with orchestration and automation platforms: The boundary between ETL tools and workflow orchestration platforms is blurring. Organizations are seeking unified solutions that can perform data extraction, transformation, and simultaneously intelligently schedule, monitor, and optimize these workflows as part of larger business processes. Instead of treating ETL jobs as isolated tasks, pipelines are managed by sophisticated tools that can coordinate multiple steps, handle dependencies, and automatically recover from errors. Essentially, ETL is becoming one piece of a broader DataOps automation framework.
- Semantic-aware ETL and metadata-driven architectures: This trend means that data pipelines will leverage rich metadata and semantic models to make smarter decisions about how to process and integrate data. In practice, a semantic-aware ETL pipeline “understands” the business meaning of data and can automatically harmonize data and enforce rules without as much hard-coded logic. For instance, a semantic layer could define what constitutes a “marketing qualified lead” or how to calculate LTV, and any ETL workflow that creates those fields would reference that central definition. This reduces the risk of different teams using different calculations. It also simplifies changes; if the business redefines a metric, updating it in the semantic layer propagates the change to all pipelines.
- Greater emphasis on privacy and regulatory-aligned ETL: This trend is all about the incorporation of advanced privacy-enhancing technologies directly into ETL processes. Privacy-first data pipelines employ techniques such as data anonymization, pseudonymization, and differential privacy to safeguard sensitive information while enabling aggregate analysis. Regulatory-aligned ETL also means being adaptable to a fragmented legal landscape. Laws differ by region, so pipelines may need dynamic behaviors, such as excluding certain data for EU residents or routing data to databases in specific regions to meet data residency requirements.
- Shift toward unified analytics pipelines: Perhaps the most transformative long-term trend is the convergence of data pipelines for BI, AI/ML, and activation into a unified analytics pipeline. Traditionally, organizations had separate processes for BI, AI/ML, and data activation. This unified pipeline approach has huge strategic implications. It enables continuous intelligence for marketing, a state where insights constantly flow from data to decision to action. Attribution models could not only calculate which ads drove sales, but the pipeline might also adjust marketing spend allocations in connected ad platforms based on those results, all automatically.
Sum Up
ETL is a foundational component of business intelligence. It transforms fragmented, siloed datasets into unified, analysis-ready sources of truth. In complex marketing and revenue environments, where data volume and velocity grow daily, a well-architected ETL process ensures data quality, governance, and scalability across the entire analytics stack.
Improvado goes beyond traditional ETL by offering a platform purpose-built for marketing analytics.
With 1,000+ prebuilt connectors, automated data normalization, and support for complex use cases such as multi-touch attribution and campaign pacing, it reduces engineering overhead and accelerates time-to-insight.
As AI becomes integral to how teams consume and act on data, Improvado’s embedded AI Agents and governance tools make it a future-ready solution.
Schedule a demo to see how it supports enterprise-grade intelligence from data ingestion to activation.


