
The explosion of marketing channels, platforms, and tools has made managing data more complex than ever.
Traditional analytics infrastructures struggle to keep pace with the volume, velocity, and variety of today’s marketing data. Teams are increasingly challenged by delayed reporting, inconsistent metrics, and fragmented customer views.
To address these challenges, more organizations are turning to the modern data stack.
This article breaks down what a modern data stack is and why it has become essential for high-performing marketing organizations. You’ll learn about its key components, how it compares to legacy systems, the business benefits it offers, and what to consider when building or evolving your own stack.
What Is a Modern Data Stack?
The core idea is to break down the data infrastructure into distinct, interoperable layers. Each layer can be optimized or replaced independently, giving teams flexibility in how they manage and evolve their analytics workflows.
From ETL pipelines and cloud storage to AI modeling and embedded analytics, the modern stack supports a wide range of marketing use cases, without the technical debt or rigidity of traditional architectures.
Evolution of data architecture
Marketing data architecture has undergone a major transformation in response to the complexity of today’s marketing ecosystem.
Ten years ago, most teams relied on siloed platforms, one-off exports, and internal BI teams to produce static reports. Each tool owned its own data, and naming conventions weren’t standardized; reporting logic was scattered across disconnected spreadsheets.
As marketing technology exploded, bringing dozens of new tools per stack, these limitations became unsustainable.
In response, the modern stack emerged. API-based connectors replace manual exports. Data warehouses centralize siloed datasets. Transformation layers clean and unify metrics. BI tools allow for self-serve exploration. And AI-driven insights are layered directly into workflows.
The shift is not just technological, it’s organizational, moving control from IT to data-savvy marketing teams.
Modern vs. Legacy data stack
| Aspect | Legacy data stack | Modern Marketing data stack |
|---|---|---|
| Data storage | On-premise databases, limited scalability | Cloud-based warehouses (Snowflake, BigQuery, etc.) |
| Data collection | Manual exports, siloed platform access | Automated connectors with hundreds of sources |
| Data transformation | Custom SQL scripts, limited reusability | Modular tools like dbt or Improvado’s engine |
| Accessibility | Data locked in BI tools, limited to analysts | Self-service dashboards and embedded analytics |
| Reporting speed | Weekly/monthly static reports | Near real-time data access for optimization |
| Team involvement | IT-managed, limited marketer autonomy | Owned by marketing and data teams collaboratively |
| Scalability | Manual scaling with infrastructure limits | Elastic scaling through cloud architecture |
| AI / Automation | Minimal or custom-built logic | Native support for AI agents and predictive models |
What Are the Benefits of the Modern Data Stack?
Adopting a modern data stack is not just about updating tools; it’s about enabling faster, smarter, and more scalable decision-making across the marketing organization.
The following benefits outline how a modern stack creates a measurable impact across performance, productivity, and business outcomes.
1. Faster time to insight
Legacy systems often delay access to marketing data due to manual exports, engineering dependencies, and fragmented storage.
A modern stack automates the entire data lifecycle, from ingestion to visualization, through automated pipelines, real-time syncs, and cloud-native infrastructure. This reduces delays and allows marketing teams to detect campaign inefficiencies, optimize budget allocation, and act on trends while they still matter.
Time-to-insight can shift from weeks to hours or even minutes, depending on the stack.
Before Improvado, a modern data stack solution, preparing reports at Signal Theory was a labor-intensive task, often taking four hours or more per report. After switching to Improvado reporting time dropped by over 80%, making the process significantly more efficient and much less stressful.
"Reports that used to take hours now only take about 30 minutes. We're reporting for significantly more clients, even though it is only being handled by a single person. That's been huge for us.”

2. Improved scalability
Campaign complexity grows rapidly, especially for agencies and enterprise teams managing dozens of clients, markets, product lines, and brands.
Modern stacks are built on elastic, cloud-first technologies that scale automatically with data volume and concurrency needs. Whether you're onboarding new clients or expanding into new channels, the infrastructure adapts without re-architecting pipelines or straining engineering bandwidth.
3. Increased autonomy for marketers
Legacy pipelines often trap marketers behind engineering bottlenecks. With a modern stack, marketers and data analysts can access, transform, and analyze data via intuitive UIs, prebuilt templates, and governed self-service tools.
This independence accelerates campaign iteration, reduces internal friction, and allows technical teams to focus on higher-leverage work like automation and modeling.
4. Reduced operational costs
Although the upfront investment may seem higher, the modern data stack reduces long-term costs by minimizing technical debt, automating manual work, and enabling reusable workflows.
Engineering resources once tied up in ETL maintenance or dashboard fixes can be shifted toward strategic initiatives, resulting in higher ROI per headcount and faster innovation cycles.
5. Greater data consistency
With disparate platforms measuring metrics like ROAS, CPA, and attribution differently, decision-makers often struggle to trust the data.
The modern stack enforces a centralized metrics layer, applying consistent business logic during the transformation process. This ensures clean, unified outputs across dashboards, embedded tools, and predictive models, minimizing discrepancies between reports and aligning stakeholders around a shared truth.
ASUS needed a centralized platform to consolidate global marketing data and deliver comprehensive dashboards and reports for stakeholders.
Improvado, a marketing-focused enterprise analytics solution, seamlessly integrated all of ASUS’s marketing data into a managed BigQuery instance. With a reliable data pipeline in place, ASUS achieved seamless data flow between deployed and in-house solutions, streamlining operational efficiency and the development of marketing strategies.
"Improvado helped us gain full control over our marketing data globally. Previously, we couldn't get reports from different locations on time and in the same format, so it took days to standardize them. Today, we can finally build any report we want in minutes due to the vast number of data connectors and rich granularity provided by Improvado."

What Are the Key Components of the Modern Data Stack?
A modern marketing data stack has a modular architecture where each layer plays a distinct role.
Below is a breakdown of the core components of a modern data stack and how they work together to deliver timely, trustworthy insights.
1. Data integration and ingestion
This is the starting point of any data pipeline — extracting data from source systems and delivering it to a centralized location.
In the marketing context, sources include platforms like Google Ads, Meta, LinkedIn, HubSpot, Salesforce, and analytics tools like GA4 or Mixpanel. Each system produces data with different schemas, update frequencies, and access protocols, making ingestion a non-trivial task.
Modern data ingestion platforms automate this process with prebuilt connectors that continuously pull and normalize data via APIs or webhooks.
They handle complex backend tasks like schema drift detection, pagination, rate limiting, retry logic, and field mapping. This ensures data flows reliably and consistently, without requiring engineering to rebuild pipelines every time an API changes.
ETL vs. ELT
When integrating data, two approaches are common: ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform).
- In a traditional ETL pipeline, data is transformed on an intermediary server before loading into the data warehouse or storage. This made sense when storage or compute in the warehouse was limited, transforming upfront reduced the load.
- With the rise of powerful cloud data warehouses, the paradigm shifted to ELT. In an ELT process, raw data is first extracted from sources, loaded directly into the warehouse in its original form, and then transformed inside the warehouse as needed.
| Aspect | ETL | ELT |
|---|---|---|
| Processing order | Data is transformed before it is loaded into the data warehouse. | Raw data is loaded first, then transformed within the data warehouse. |
| Data freshness | Can introduce delays due to transformation before loading. | Raw data lands quickly for immediate access or partial use. |
| Flexibility for marketing teams | Less flexible if you want to explore raw data or adjust definitions later. | More flexible; you can define, revise, and reprocess transformations without reloading. |
| Use cases | Ideal when data quality and standardization are non-negotiable before analysis. | Preferred when speed and experimentation are key, such as rapid campaign analysis. |
| Cost Efficiency | Lower compute cost before cloud warehouses existed; cost grows with large data volumes. | More cost-effective in cloud-first environments with pay-per-query or scalable warehouse pricing. |
Popular data integration tools
To streamline data ingestion, many enterprises turn to specialized integration tools rather than building pipelines from scratch. Some of the popular options include:
- Improvado: A marketing-focused marketing analytics and data platform with a robust ETL/ELT. It offers 1,000+ pre-built connectors, pre-built data models to map disparate metrics, multiple storage options, and up to 10 years of historical data ingestion. Improvado is purpose-built to handle high-volume marketing use cases and requires zero coding.
- Fivetran: A general-purpose cloud ELT platform with a library of 700+ pre-built connectors spanning databases, SaaS apps, and advertising sources. To transform data, Fivetran integrates with dbt.
- Airbyte: An open-source ELT tool that provides a framework to build and run your own data connectors. Companies can self-host Airbyte or use its cloud service.
2. Data storage and warehousing
Once data is ingested, it lands in the storage and analytics layer of the modern data stack.
For marketing, centralized storage eliminates the need for fragmented campaign data across multiple spreadsheets and platforms. It enables unified views of customer behavior, multi-touch attribution models, and cross-channel performance tracking.
Popular cloud data warehouses
- Google BigQuery: A serverless data warehouse designed for scale and speed. It integrates tightly with the Google ecosystem, making it a strong choice for teams already using Google Ads, Analytics, or Sheets.
- Snowflake: A fully managed cloud data platform that separates storage and compute, allowing for scalable, concurrent workloads. It supports structured and semi-structured data, and is known for its ease of use and support for cross-cloud deployment.
- ClickHouse: An open-source, columnar database optimized for real-time analytics. It excels at high-speed queries over large volumes of event data, making it ideal for marketing teams handling large, time-series datasets.
Another storage option is a data lake or data lakehouse.
- A data lake is a centralized repository that stores raw data in its native format, structured, semi-structured, or unstructured. It’s ideal for marketing teams dealing with large, diverse datasets from web traffic, social platforms, ad networks, and CRM systems.
- A data lakehouse merges the flexibility of a data lake with the data management features of a traditional data warehouse. It supports both raw data ingestion and structured queries, making it suitable for teams that want to run reporting, AI models, and analytics from a single source.
3. Data transformation
Raw data from source systems is rarely analytics-ready. Transformation is the process of cleaning, structuring, mapping, and enriching the data to make it usable.
This includes:
- Standardizing naming conventions across platforms (for example, metrics like 'cost' and 'spend'),
- Calculating derived metrics (for example, ROAS, CPA),
- Handling missing or incorrect entries,
- Aligning date formats, time zones, and currencies,
- Stitching customer journeys across devices or channels,
- Applying business rules or definitions (for example, revenue allocation, custom UTM logic).
By transforming data, companies create data models — curated tables or views that represent key business metrics and entities, such as a table of marketing funnel stages or a unified customer profile.
Tools like dbt, Coalesce, or transformation layers built into platforms like Improvado allow teams to codify business logic once and reuse it across dashboards and models.
To simplify and speed up the data transformation process, Improvado provides a no-code data transformation framework and a number of pre-built data models for common marketing use-cases.
One client decided to test Improvado's scalability, combining 15 data sources and mapping up to 50 fields in a complex custom data model. The platform's capacity to handle such complex transformations far exceeded their previous experiences.
“Once the data's flowing and our recipes are good to go—it's just set it and forget it. We never have issues with data timing out or not populating in GBQ. We only go into the platform now to handle a backend refresh if naming conventions change or something. That's it.”

4. Business intelligence and analytics
Once data has been centralized and transformed into useful models, the next layer of the modern data stack is business intelligence (BI) and analytics. This is where data turns into insights through dashboards, reports, and data exploration interfaces that business users can interact with.
Business intelligence platforms sit on top of a centralized data store and enable teams to create dashboards, generate reports, visualize trends, and monitor performance across channels.
Popular BI tools, such as Looker, Tableau, and Power BI, allow analysts to slice and dice marketing data, uncover performance trends, and build automated reports for various stakeholders, from campaign managers to executives.
More recently, AI reporting tools, more specifically AI agents, have emerged as an advanced extension of the analytics layer.
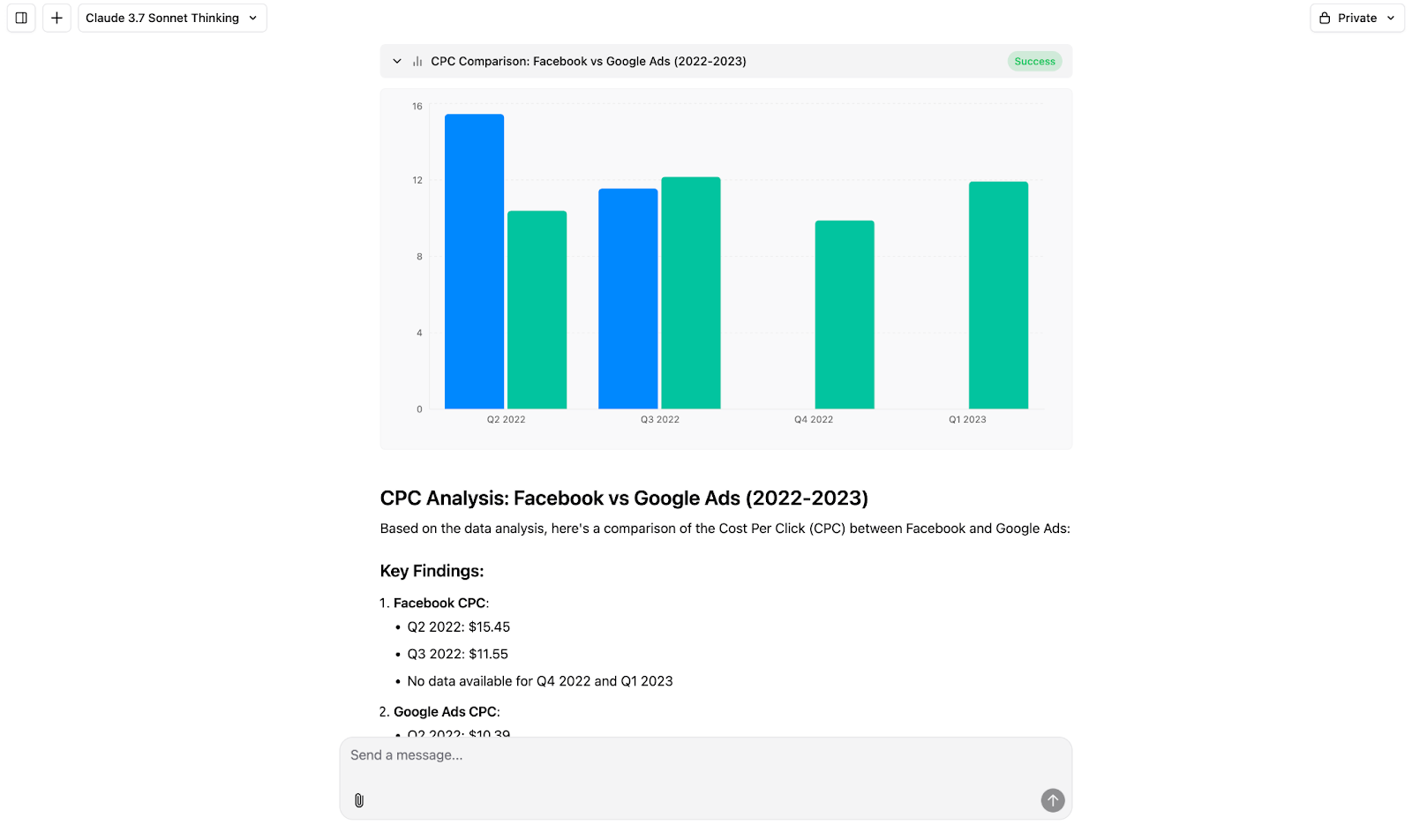
These agents provide a natural language interface for querying data, allowing marketers and analysts to get answers without writing SQL or navigating complex dashboards.
In addition to conversational querying, AI Agents can proactively surface insights, summarize performance, detect anomalies, and streamline reporting workflows.
Function Growth, a performance marketing agency for D2C brands, was losing hours each week to manual campaign analysis. This slowed down their ability to act on insights and limited the scale at which they could optimize performance.
With Improvado’s AI-powered reporting, Function Growth now gets instant insights across all client accounts, saving six hours weekly. The team quickly identifies which campaigns to scale and which to fix, unlocking opportunities that were previously buried in the data.
Statistical analysis is only as good as the person analyzing the data. With Improvado's AI, we can uncover insights that might otherwise be overlooked.

5. Reverse ETL and data activation
After deploying a solid pipeline that goes from raw data to BI insights, organizations often encounter a new question: how can we operationalize these insights.
Dashboards and reports are great for decision-making, but often the real value of data lies in driving actions. This is where reverse ETL, also known as data activation, comes into play.
The goal of reverse ETL is to bridge the gap between data teams and business teams by delivering actionable data to the tools where work actually happens.
For example, once a high-intent audience segment is defined in the warehouse, reverse ETL pushes it to Meta Ads or other ad platforms for campaign targeting. This closes the analytics-to-activation loop.
How to Build a Modern Data Stack?
Building a modern data stack requires aligning technology decisions with business needs, especially around marketing performance, customer insights, and speed to insight.
Here are a set of steps an organization needs to go through to build its own modern marketing data stack:
- Define your goals and data use cases: Clarify what problems your data stack needs to solve and identify key stakeholders and the types of decisions they make so you can align technical design with business needs from the start.
- Map your data sources: List all platforms generating valuable marketing data. Pay attention to source reliability, API quotas, historical data limits, and frequency of required refresh. Consider how deeply you'll need to extract (ad-level, campaign-level, keyword-level), which impacts integration choice and cost.
- Select a data ingestion and integration tool: Select a platform that can reliably extract data from your sources and deliver it to your warehouse. Look for built-in connectors, transformation logic, and support for marketing-specific APIs.
- Select your central storage option: Choose between a cloud data warehouse, a data lake, or a lakehouse. Warehouses are ideal for structured analytics, while lakehouses enable the combination of structured and unstructured data. For marketing, a warehouse is often the fastest route to reporting and attribution workflows. Consider cost, performance, ecosystem compatibility, and your team's SQL skill level.
- Establish a transformation layer: Map your business logic, naming conventions, channel groupings, KPI definitions, budget taxonomies. Use dbt or a built-in tool like Improvado's transformation engine to clean, normalize, and join data.
- Deploy your analytics and BI stack: Add a visualization layer to explore data, build dashboards, and monitor performance. Choose tools that non-technical stakeholders can use and consider AI Agents for natural language querying, alerting, and insight surfacing.
- Enable reverse ETL and data activation: Push cleaned, modeled data back into the tools your team uses every day, such as ad platforms, CRMs, or customer support tools, to enable smarter decisions and automations.
- Ensure governance and scalability: Document data models, naming conventions, and metric definitions. Assign ownership and build systems that scale with team growth and increased data complexity.
- Monitor and optimize: Set up data quality checks, performance alerts, and usage audits to ensure optimal performance. Continuously optimize integrations, dashboards, and activation workflows based on real-world use.
Modern Data Stack Challenges and Considerations
While the modern data stack offers speed, scalability, and flexibility, it’s not without trade-offs. As teams adopt new tools and architectures, they face technical, operational, and organizational challenges that can impact performance, costs, and trust in data.
Understanding these early helps avoid downstream issues and build a more resilient stack.
1. Data governance and quality assurance
The flexibility of modern stacks introduces a tradeoff: inconsistent naming conventions, duplicated metrics, and uncontrolled access can degrade trust in data. When different teams transform data differently, “multiple versions of the truth” emerge.
Establishing robust governance, such as centralized transformation layers, documented metric definitions, and clear data ownership, is essential to maintain integrity as your stack evolves.
2. Skill gaps and team alignment
Modern tools often assume technical proficiency in SQL, dbt, or cloud architecture. However, many marketing teams operate with mixed skill sets, resulting in knowledge silos or inefficient handoffs between analysts, engineers, and campaign managers.
To bridge this gap, organizations must invest in training, enforce documentation standards, and adopt tools with user-friendly interfaces, such as drag-and-drop transformations or AI-powered query layers.
3. Cost management at scale
While usage-based pricing models seem attractive initially, costs can escalate quickly with high-volume data pipelines, frequent dashboard refreshes, and multi-environment workloads. Warehousing, transformation, and reverse ETL all introduce compute and storage costs that aren’t always visible upfront.
Marketing leaders need to monitor query performance, data freshness requirements, and compute usage to avoid budget surprises. Right-sizing integrations and applying cost controls early can prevent sprawl.
4. Tool overload and fragmentation
Adopting best-of-breed tools often creates a fragmented ecosystem, which can lead to fragmented workflows and siloed data if not managed carefully.
Without a strong governance and orchestration layer, teams risk duplicating efforts, losing visibility across systems, and struggling to maintain a cohesive data strategy.
When selecting components for your stack, consider interoperability and exit strategies. Favor open standards, flexible APIs, and composable architectures that allow you to evolve your stack without complete rebuilds.
5. Schema drift
Modern data pipelines are fast and flexible, but they’re also sensitive to upstream changes. Something as small as renaming a column in a media buying platform or changing a data format from a CRM can silently break models and dashboards downstream.
This is especially problematic for marketing analytics teams working with third-party APIs and dynamic data schemas.
Without formalized data contracts and agreements between data producers and consumers regarding schema expectations and update policies, teams are left reactive instead of proactive.
Schema drift can erode trust in analytics outputs and create unnecessary firefighting cycles. Embedding schema validation and versioning in the pipeline is critical to maintaining reliability at scale.
Future Trends in Modern Data Stack
As data and AI technologies continue to evolve, several key trends are shaping how organizations will manage, analyze, and activate data in the near future.
Understanding these shifts enables teams to stay ahead of the curve and make informed technology decisions that support long-term growth.
1. Real-time and streaming analytics maturity
Real-time analytics has matured to the point where marketing teams can get up-to-the-minute insights and act immediately. Businesses are no longer satisfied with batch processing that delivers insights after the fact.
Modern data ingestion tools now often support change data capture (CDC) for real-time sync, minimizing lag between events and the data warehouse.
The strategic value is clear: faster insights lead to faster decisions.
2. AI-augmented data transformation and modeling
Artificial intelligence is becoming deeply embedded across the stack, from predictive modeling to automated transformation logic and campaign recommendations.
In 2026, many data tools include AI assistants that can auto-generate SQL code, suggest data models, and even optimize transformation logic. This trend of AI-augmented data preparation reduces manual effort and opens advanced analytics to a wider audience.
Natural language interfaces driven by AI are also making analytics more accessible – even non-technical users can ask questions of their data in plain English and let AI translate it to queries. Overall, AI-augmented data transformation means marketing teams can generate deeper insights with less effort.
3. Increasing role of reverse ETL and data activation
In traditional analytics, data flows one way: from source systems into a warehouse and then into dashboards.
Reverse ETL flips that script by pushing insights from the warehouse back into operational tools. This data activation has become a critical last-mile in the modern data stack.
The implications for marketing analytics are huge. With reverse ETL, a segment of high-value customers identified in analysis can be automatically sent to an email marketing tool for a tailored campaign, or a propensity-to-churn score can flow into a customer success platform to trigger an intervention. This closes the gap between insight and execution.
Essentially, reverse ETL ensures that the rich insights from your marketing analytics don’t just live in a dashboard but reach the front lines of marketing campaigns. It’s turning analytics into action, thereby increasing the ROI of data work by directly influencing customer experience and marketing outcomes.
4. Embedded and in-workflow analytics
Another trend shaping marketing analytics is the embedding of data insights directly into everyday tools and workflows. Rather than requiring users to log into a separate BI platform, modern analytics solutions can be embedded in CRM interfaces, project management tools, intranet portals, or any application where decisions are made.
Embedding analytics in the workflow brings data to users at the point of decision. Marketers benefit by not having to switch contexts or chase down reports; the relevant metrics are visible in the same system where they plan and execute campaigns.
This leads to more data-driven decisions (driven by higher user adoption) because insights are integrated into tools the team already uses.
5. Multi-cloud and interoperable environments
Enterprises are increasingly adopting multi-cloud strategies, using a mix of cloud providers and on-premise systems, and this is influencing data stack design.
Marketing tools are now built with cloud-agnostic capabilities to run on AWS, Azure, or Google Cloud, as well as open standards for data exchange. Data pipelines are designed to pull from and push to diverse storage locations, and technologies help workflows run in hybrid settings.
Essentially, flexibility and integration are the name of the game: the stack must work wherever the data lives and avoid vendor lock-in.
These trends collectively point toward a marketing analytics function that is always on, intelligence-driven, and holistically integrated into business operations. Marketing teams that embrace real-time, AI-augmented, well-governed, and privacy-safe analytics workflows will be positioned to measure what matters, anticipate what’s next, and activate insights at scale.
Conclusion
The strategic value of the modern data stack is evident in more effective campaign measurement, richer customer segmentation, accurate attribution modeling, and nimble performance benchmarking. Adopting a modular, AI-enhanced stack has become a competitive advantage.
Improvado offers a modern platform purpose-built for marketing data. From governed pipelines to embedded analytics and AI Agents, it helps teams centralize, normalize, and activate data at scale.
Book a demo to see how your team can unlock the full potential of your marketing data.


