
Data warehousing is a non-negotiable for businesses wanting to leverage insights and make informed decisions. A warehouse helps manage and analyze large volumes of marketing and sales data from different sources, giving marketing departments insights into customer behavior and marketing performance.
But making the right choice can be daunting, as there are seemingly endless data warehouse options on the market today.
This article explores the features, pricing, and pros and cons of each warehouse and suggests one solution for how to get all the benefits of a marketing data warehouse without dealing with any of the drawbacks
Key Takeaways:
- A data warehouse is a central repository for structured and semi-structured data. It is designed for fast query and analysis.
- Cloud data warehouses like Snowflake, BigQuery, and Redshift offer superior scalability, flexibility, and cost-efficiency compared to on-premise options.
- Key features to look for include the separation of compute and storage, MPP architecture, and support for real-time data ingestion.
- Choosing the right solution requires assessing your data volume, use cases, integration needs, and technical expertise.
- Automated data integration tools like Improvado are essential to populate your data warehouse without manual effort, ensuring data is analysis-ready.
What Is a Data Warehouse Solution? A Foundational Overview
A data warehouse solution is a centralized analytics system built for structured reporting and decision support. It consolidates data from operational systems such as CRM, ERP, ecommerce platforms, and marketing tools. Unlike transactional databases, it is optimized for complex queries across large historical datasets.
A modern data warehouse typically provides:
- Centralized storage for integrated, historical, and current data
- Schema modeling optimized for analytical workloads
- High-performance query engines for large aggregations
- Support for BI tools, dashboards, and advanced analytics
- Separation of compute and storage in cloud-native platforms
Its purpose is not transaction processing. It is analytical depth, consistency, and speed.
Data Warehouse vs. Data Lake vs. Database: Key Differences
People often confuse these terms. Each serves a distinct purpose.
| System | Primary Function | Data Type | Optimization Focus |
|---|---|---|---|
| Database (OLTP) | Operational transactions | Structured | Fast inserts and updates |
| Data Warehouse (OLAP) | Analytical reporting | Structured, modeled | Large-scale queries and aggregations |
| Data Lake | Raw data storage | Structured and unstructured | Flexible storage, later processing |
A data warehouse stores cleaned, modeled, and governed data. A data lake stores raw data for future transformation. A transactional database handles real-time operations.
Core components of a warehouse architecture include:
- Data sources (CRM, ads platforms, finance systems, applications)
- ETL/ELT pipelines to extract and transform data
- Storage layer for structured datasets
- Metadata and governance controls
- Access layer via BI tools, SQL, or analytics platforms
The warehouse becomes the analytical backbone. Its effectiveness depends on clean ingestion, consistent transformations, and governed data models.
Why Your Business Needs a Data Warehouse Solution
Implementing a data warehouse solution offers significant competitive advantages. It transforms raw data into a strategic asset. Businesses that leverage data effectively consistently outperform their peers.
Achieving a Single Source of Truth
Different departments often use different data sources. This leads to conflicting reports and metrics. A data warehouse solves this problem. It consolidates all your data. It creates a single, trusted version of the truth. This alignment is critical for strategic planning.
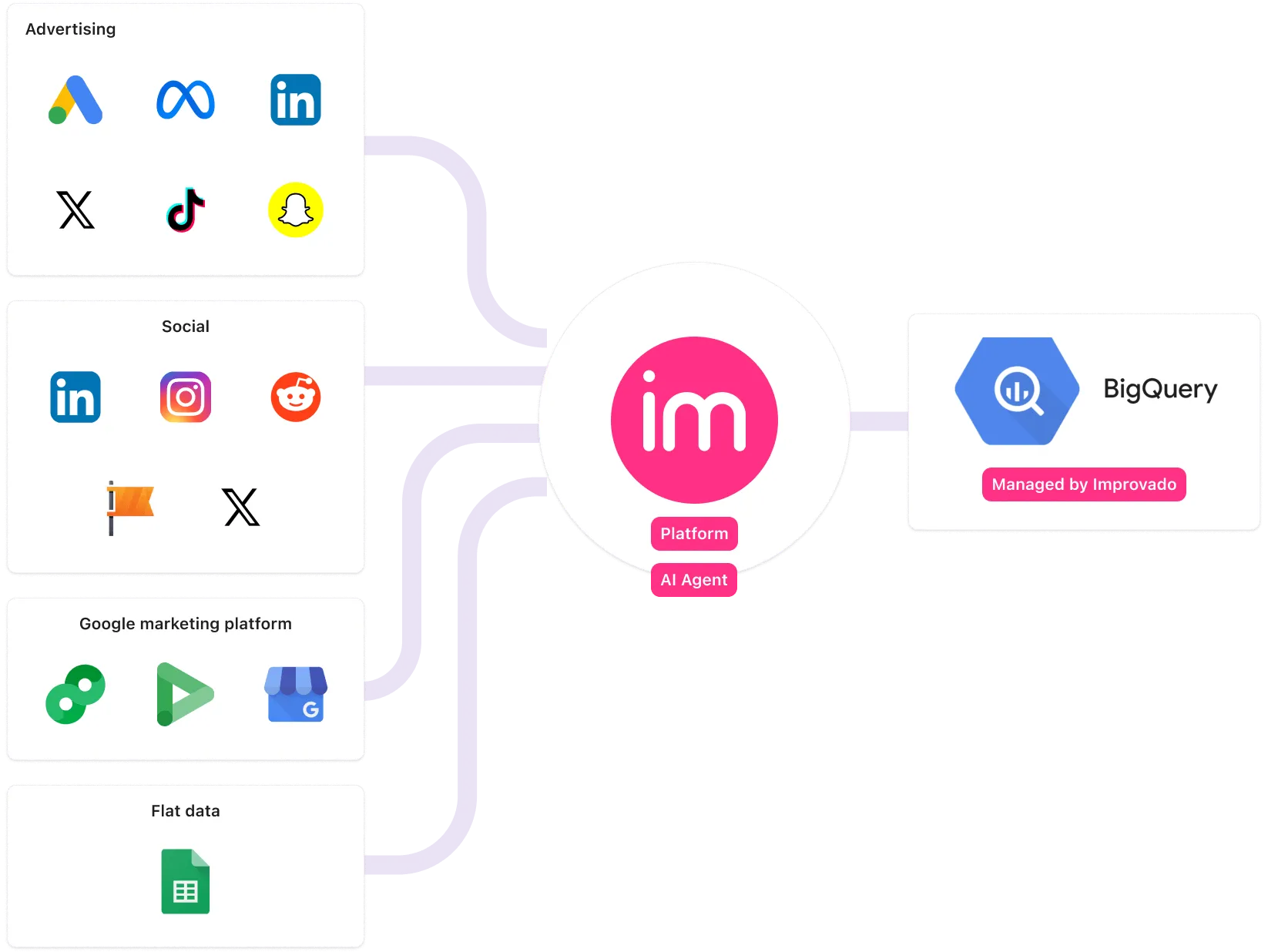
ASUS needed a centralized platform to consolidate global marketing data and deliver comprehensive dashboards and reports for stakeholders.
Improvado, a marketing-focused enterprise analytics solution, seamlessly integrated all of ASUS’s marketing data into a managed BigQuery instance. With a reliable data pipeline in place, ASUS achieved seamless data flow between deployed and in-house solutions, streamlining operational efficiency and the development of marketing strategies.
"Improvado helped us gain full control over our marketing data globally. Previously, we couldn't get reports from different locations on time and in the same format, so it took days to standardize them. Today, we can finally build any report we want in minutes due to the vast number of data connectors and rich granularity provided by Improvado."

Enabling Advanced Business Intelligence and Reporting
Data warehouses are optimized for high-speed queries. This allows users to run complex reports quickly. You can explore trends, patterns, and anomalies in your data. It powers dashboards in tools like Tableau or Power BI. This self-service analytics empowers everyone in your organization to make data-driven decisions.
Unlocking Predictive Analytics and Machine Learning
A clean, centralized dataset is the foundation for advanced analytics. Data scientists can use the historical data in a warehouse to build predictive models. These models can forecast sales, identify at-risk customers, and optimize operations.
Modern data warehouses often have built-in machine learning capabilities to simplify this process.
Enhancing Data Governance and Security
Centralizing data makes it easier to manage and secure. A data warehouse provides a single point of control for data access. You can implement robust security policies. It also helps with compliance for regulations like GDPR and CCPA. A strong data governance framework ensures data quality and consistency.
Driving Better Marketing ROI
For marketers, a data warehouse unifies data from all channels. This includes social media, Google Ads, email, and offline sources. With a complete view of performance, you can optimize campaigns effectively. This leads to a measurable increase in your marketing ROI and proves the value of your efforts.
Types of Data Warehouse Solutions: Choosing Your Architecture
Data warehouse solutions can be deployed in several ways. The right choice depends on your organization's resources, expertise, and strategic goals. Understanding the main architectural types is the first step.
On-Premise Data Warehouses: Control and Customization
On-premise solutions are hosted on your own servers. This gives you complete control over your hardware and data. It can be ideal for organizations with strict security or regulatory requirements.
However, it requires a significant upfront investment. You also need a skilled IT team for maintenance and management.
Cloud Data Warehouses: Scalability and Flexibility
Cloud data warehouses are hosted by a third-party provider like AWS, Google, or Microsoft. This model eliminates the need for physical infrastructure. It offers pay-as-you-go pricing and incredible scalability. You can scale your storage and computing resources up or down in minutes. This makes it a cost-effective and agile choice for most businesses.
Hybrid Data Warehouses: The Best of Both Worlds
A hybrid approach combines on-premise and cloud solutions. It allows you to keep sensitive data on-premise while leveraging the cloud's scalability.
This can be a good transitional strategy for companies moving to the cloud. It offers flexibility but can add complexity to data management.
| Aspect | On-Premise Warehouse | Cloud Warehouse | Hybrid Warehouse |
|---|---|---|---|
| Deployment | Internal servers | Third-party provider | Combination of both |
| Cost Model | High upfront capital expense (CapEx) | Pay-as-you-go operational expense (OpEx) | Mixed model, can be complex |
| Scalability | Limited and slow to scale | Elastic and nearly infinite | Flexible but requires careful planning |
| Control | Full control over hardware and data | Provider manages infrastructure | Control over on-premise components |
| Maintenance | Managed entirely by internal IT teams | Managed by the cloud provider | Shared responsibility |
| Best For | Organizations with strict security needs or legacy systems | Most businesses, from startups to enterprises | Organizations migrating to the cloud or with specific data residency needs |
Top 6 Data Warehouse Platforms for 2026
The market for data warehouse solutions is dynamic and competitive. We've evaluated the top platforms based on performance, scalability, ease of use, and cost. This list will help you find the best fit for your requirements.
1. Google BigQuery
As a powerful cloud-based data warehouse, Google BigQuery is an ideal tool for organizations of all sizes to store large amounts of data and easily access it with fast query performance.
Features
The BigQuery serverless architecture eliminates the need for businesses to manage infrastructure. Thus, data engineers and analysts focus on what matters the most: data analysis and insights.
BigQuery has a built-in machine learning capability, allowing you to integrate it with Cloud ML and TensorFlow for powerful AI models. It also can execute queries on petabytes of data in seconds for real-time analytics. BigQuery supports geospatial analytics, which helps users to see the bigger picture of marketing events and make more accurate predictions.
The warehouse integrates seamlessly with other Google Cloud Platform services and popular data visualization and analysis tools, such as Tableau, Power BI, or Looker Studio.
BigQuery supports standard SQL queries, Java, Python, C#, Go, Node.js, PHP, and Ruby client libraries.
Pricing
Pricing for Google BigQuery is based on storage and query costs. Storage is differentiated as active or long-term, with the latter being data stored in partitions that have not been modified in more than 90 days.
The cost for active Google BigQuery storage is $0.020 per GB/month, and long-term storage is $0.010 per GB/month, with the first 10 GB/month being free for both types.
BigQuery offers two pricing models for queries: on-demand and flat-rate. On-demand pricing for Google BigQuery is $5 per TB, with 1 TB free monthly. Monthly flat-rate pricing is billed at $10,000 per 500 slots.
Pros
- Fast query performance
- The serverless structure paves the way for handling large datasets, making it a scalable solution
- Ability to run multiple queries in parallel without any additional setup
- Seamless integration with other Google Cloud Platform services, as well as popular data visualization and analysis tools
- No need for businesses to manage infrastructure
Cons
- Trying to utilize several SQL dialects can be confusing
- Data expiration features limitations
- A lack of support for updates and deletions
- The pay-as-you-go pricing model can become pricey for enterprise companies with heavy data processing needs
- A steeper learning curve
2. Amazon Redshift
Amazon Redshift is a fully-managed data warehousing service that provides fast query performance and automatic scaling. It's suitable for high-speed data analytics, allowing marketing departments to process petabytes of data in seconds.
Features
The Redshift warehouse supports both row- and column-oriented data storage. With its columnar storage, Redshift can process queries quickly and efficiently, enabling businesses to gain insights in near real-time.
Redshift supports automatic concurrency scaling for executing hundreds of concurrent queries without additional overhead. Teams can optimize their data warehouse performance and reduce operational costs.
The warehouse supports standard SQL queries, while its simple and intuitive interface requires no specialized knowledge or expertise.
Pricing
Amazon Redshift has two pricing structures. The first option starts at $0.25 per hour. But the price can increase depending on how many computers are in a cluster.
The second is a managed store pricing structure, starting at $0.024 per GB of data per month. The price varies between regions and doesn’t include the cost of storing backups.
Pros
- High-speed query performance
- Support for automatic concurrency scaling
- Ability to scale clusters or switch between node types
- Advanced analytics features, including machine learning and predictive analytics
Cons
- No multi-cloud server options
- Not a serverless infrastructure
- Unpredictability in query response times: query performance can vary depending on the complexity of the query and the size of the data being processed
- Limited query flexibility in handling simple queries
3. PostgreSQL
PostgreSQL is an open-source data warehouse tool that enables users to store and query large amounts of data. It has built-in features such as Multi-Version Concurrency Control (MVCC), allowing users to optimize the performance of their databases.
Features
PostgreSQL is one of the most popular databases designed to process large volumes of data and complex data types and procedures.
PostgreSQL supports SQL and JSON querying, enabling developers to integrate it with their applications. You can also utilize the PostGIS extension, a geospatial data library that allows you to offer location-based business solutions.
PostgreSQL supports advanced SQL features, including subqueries, window functions, and common table expressions, making it a powerful tool for data analysis. On the flip side, PostgreSQL warehouse management requires a lot of IT resources and technical expertise.
Pricing
PostgreSQL is open-source and free to use. However, if you want security patches, maintenance updates, and technical support, you may have to pay for them.
Pros
- Open-source and free to use
- Easily add more functionality through custom extensions
- Supports both SQL and JSON querying
- Optimized database performance with MVCC
Cons
- Running it locally can be challenging
- No automatic scaling capabilities
- Requires manual setup and maintenance
- A steeper learning curve compared to other data warehouse solutions
4. Microsoft Azure
Microsoft Azure is a cloud-based relational database that offers fast query performance and automatic scaling. It employs a node-based system and uses massively parallel processing (MPP), allowing users to extract and visualize business insights much faster.
Features
Azure SQL Data Warehouse is designed with a massively parallel processing architecture, allowing businesses to scale computing and storage resources as their needs grow.
Azure SQL is compatible with hundreds of MS Azure resources, such as Power BI, Azure Active Directory, Azure Machine Learning, and others. It enables you to scale up or down without downtime and run multiple queries in parallel without additional setup.
Azure SQL Data Warehouse supports advanced analytics features, including machine learning and predictive analytics. It allows marketing teams to go deep with their data and derive valuable insights that otherwise would be left unnoticed.
Pricing
Azure SQL pricing starts at $0.52 per V-core/hour, and storage cost is $0.115 per GB/hour with a minimum of 5GB and a maximum of 4TB. Additional charges for backup storage are $0.20 per GB/month.
Pros
- Fast query performance and the ability to run multiple queries in parallel
- Compatibility with MS Azure resources
- Highly scalable architecture and automatic scaling capabilities
Cons
- High costs for large databases
- Scaling can cause latency issues
- A limited set of third-party tooling compared to other data warehousing solutions
5. IBM Db2 Warehouse
IBM Db2 Warehouse is a fully-managed, cloud-based data warehousing solution with a built-in machine learning tool that allows users to train and deploy ML models using SQL and Python.
Features
The platform provides an intuitive user interface or REST API for managing storage and processing power, and the elastic scaling of workloads. And like Microsoft Azure, it supports MPP capabilities, enabling users to execute hundreds of concurrent queries without additional overhead.
IBM Db2 Warehouse supports advanced analytics features, including machine learning, geospatial and predictive analytics. This, together with fast ingest and querying, helps you tap into real-time insights and optimize your strategy on the go.
Additionally, IBM Db2 Warehouse supports a wide range of data sources and provides multiple ways to load and extract data.
Pricing
IBM Db2 Warehouse offers nine pricing tiers, ranging from Flex One (the most basic tier) to Elastic Compute. Cost starts at $0.68 per instance/hour and varies depending on the number of nodes in a cluster.
Pros
- Easy integration with other tools
- High-speed query performance
- Supports automatic concurrency scaling
- Ability to scale clusters or switch between node types
Cons
- Can be slow to roll out new features compared to other data warehouse tools
- Higher up-front investments for reserved instances
- Has a steep learning curve and can be complex to set up and use
6. Snowflake
Snowflake is a cloud-based data warehouse solution that provides enterprise-grade scalability and security. It uses a multi-cluster shared architecture to separate storage from processing power, allowing users to scale CPU resources based on user activities.
Features
Snowflake also offers integration with PostGIS extension for spatial analysis, SQL and JSON querying capabilities, query optimizers and accelerators, data lake storage integration, and automatic scaling. It supports many external data sources, including Apache Kafka, AWS S3, and Microsoft Azure.
Snowflake separates data storage and processing, making it more flexible and cost-effective than traditional data warehousing solutions. The warehouse is optimized for handling large volumes of data and complex queries, providing fast and reliable performance.
Pricing
Snowflake pricing is based on per-second billing, with a minimum of 60 seconds. Compute costs vary according to the region, platform, and pricing tier. The average compute cost for the Standard tier is $0.00056 per second per credit, while the same is $0.0011 per credit. Storage cost is $0.115 per GB/hour with no additional charges for backup storage.
Pros
- Fast query performance
- Ability to run multiple queries in parallel
- Compatibility with MS Azure resources
- Automatic scaling capabilities
Cons
- High costs for large databases
- Scaling can cause latency issues
- Limitations with unstructured data
Head-to-Head Comparison: The Best Data Warehouse Products
Choosing between these powerful platforms can be challenging. This table provides a quick side-by-side comparison of their key characteristics to help you decide.
| Solution | Architecture | Scalability Model | Pricing Model | Best For |
|---|---|---|---|---|
| Google BigQuery | Serverless, MPP | Automatic, Elastic | Pay-per-query and storage | Real-time analytics and ease of use |
| Amazon Redshift | Cluster-based, MPP | Cluster resizing, concurrency scaling | Pay-per-node-hour | Deep AWS integration and large datasets |
| Snowflake | Multi-cluster, shared data | Independent compute and storage scaling | Pay-per-second for compute, per-TB for storage | Flexibility, multi-cloud and data sharing |
| Azure Synapse | MPP, Unified Analytics | Scale dedicated or serverless pools | Pay-per-hour for dedicated compute | Unified big data and analytics in Azure |
| IBM Db2 Warehouse | Cluster-based, MPP | Elastic cluster scaling | Pay-per-instance-hour | In-database machine learning |
| PostgreSQL | Single-node (by default) | Manual vertical or horizontal scaling | Free (self-hosted costs apply) | Startups and small-scale warehousing |
How to Choose the Right Data Warehouse Solution
Selecting the right data warehouse product is a critical decision. Follow this step-by-step process to ensure you make the best choice for your organization's future.
Step 1: Assess Your Data Volume and Velocity
Start by understanding your data. How much data do you have now? How fast is it growing? If you are dealing with terabytes or petabytes, you need a highly scalable cloud solution. Consider if you need to process data in real-time or if batch processing is sufficient.
Step 2: Define Your Use Cases and Analytics Requirements
What questions do you need to answer? Will you be running simple reports or complex machine learning models? Define your primary use cases. This will help you prioritize features like ML capabilities, real-time analytics, or support for semi-structured data.
Step 3: Evaluate Integration Capabilities with Your Data Sources
Your data warehouse is only as good as the data in it. Make a list of all your data sources. Ensure the solution you choose can easily connect to them. This is where an ELT tool like Improvado becomes invaluable. It bridges the gap between your sources and your warehouse.
Step 4: Analyze Scalability and Performance Needs
Think about your future needs. Your business will grow, and so will your data. Choose a solution that can scale with you. Cloud warehouses with independent scaling for compute and storage offer the most flexibility. Performance is also key; test query speeds with your own sample data if possible.
Step 5: Compare Pricing Models and Total Cost of Ownership (TCO)
Look beyond the sticker price. Cloud pricing models can be complex. Consider costs for storage, compute, data ingestion, and data egress. Calculate the Total Cost of Ownership (TCO). This includes software costs, infrastructure, and the personnel needed for management.
Step 6: Consider Your Team's Technical Expertise
Be realistic about your team's skills. A serverless solution like BigQuery requires less management than a cluster-based one like Redshift. If you don't have dedicated data engineering resources, a fully-managed service is the best choice. This will reduce your operational overhead.
The Role of ETL/ELT in Data Warehouse Solutions
A data warehouse is an empty box without data. The process of getting data into your warehouse is called data integration.
A data integration pipeline typically performs three core steps:
- Extract data from APIs, databases, or applications
- Transform or standardize schemas, metrics, and formats
- Load data into the warehouse storage layer
Two architectural models dominate: ETL and ELT.
| Model | Sequence | Where Transformation Happens | Typical Use Case |
|---|---|---|---|
| ETL | Extract → Transform → Load | External processing server | Legacy or on-premise systems |
| ELT | Extract → Load → Transform | Inside the warehouse | Cloud-native environments |
ETL transforms data before it reaches the warehouse. It was designed for environments with limited warehouse compute capacity. It centralizes transformation logic but creates additional infrastructure overhead.
ELT loads raw data first and applies transformations within the warehouse engine. Modern cloud platforms provide elastic compute, making in-warehouse transformations faster and more scalable. ELT supports rapid schema changes, large-scale joins, and iterative modeling without rebuilding pipelines.
Pipeline reliability directly affects reporting accuracy. Manual API scripts, schema changes, and inconsistent metric logic create instability. Automated ELT platforms reduce this risk.
Improvado operates as an automated ELT layer for marketing and revenue data. It provides pre-built connectors to over 500 platforms. It extracts data, standardizes schemas, aligns metric definitions, and loads structured datasets into warehouses such as Snowflake or BigQuery. Transformations are applied inside the warehouse, preserving flexibility and performance.
The warehouse provides storage and compute. Improvado ensures consistent ingestion, normalization, and governance before analytics begin.
For marketing teams, data ingestion and transformation often require substantial technical effort. Improvado streamlines the entire process with pre-built marketing-specific transformation recipes, automated normalization, and no-code customization. This dramatically reduces setup time, minimizes manual errors, and accelerates the path from raw data to trustworthy insights.
“Once the data's flowing and our recipes are good to go—it's just set it and forget it. We never have issues with data timing out or not populating in GBQ. We only go into the platform now to handle a backend refresh if naming conventions change or something. That's it.”

Future Trends in Data Warehousing
Data warehousing in 2026 is no longer limited to structured reporting. It is becoming the foundation for AI systems, real-time decision engines, and governed data ecosystems. Architectural decisions now determine how quickly organizations can experiment, deploy models, and respond to operational signals.
Key shifts are redefining how warehouses are designed and used.
The Rise of the Data Lakehouse
The traditional separation between data lakes and data warehouses is narrowing. The lakehouse model combines low-cost object storage with structured query engines and governance layers.
This architecture allows raw and structured data to coexist in one environment. It supports BI dashboards, advanced analytics, and machine learning pipelines without duplicating storage layers. Open table formats such as Delta Lake and Apache Iceberg improve data reliability and version control.
The goal is consolidation. One platform for structured reporting, exploratory analysis, and AI workloads. This reduces data movement and lowers operational complexity.
AI-Driven Data Operations
Artificial intelligence is now embedded directly into warehouse platforms. AI assists with:
- Automatic query optimization
- Workload management and resource allocation
- Index and partition recommendations
- Anomaly detection in data pipelines
- Automated data quality monitoring
This shifts warehouse management from manual tuning to policy-driven automation. Data teams spend less time maintaining infrastructure and more time designing models and governance frameworks.
AI is also being applied at the semantic layer. Natural language interfaces allow users to query warehouse data without writing SQL. This expands analytical access while maintaining centralized control.
Real-Time and Streaming Analytics
Batch reporting is no longer sufficient. Modern use cases require sub-minute data availability.
Warehouses now integrate directly with streaming frameworks and event ingestion services. They support incremental updates, micro-batching, and near real-time transformations. This enables:
- Live performance dashboards
- Dynamic pricing and bidding models
- Real-time personalization
- Fraud detection and risk scoring
The architectural focus is shifting from nightly refresh cycles to continuous data flow.
Data Governance and Compliance by Design
Regulatory pressure is increasing. Privacy laws, regional data residency requirements, and audit mandates are reshaping warehouse architecture.
Future-ready warehouses emphasize:
- Fine-grained access controls
- Role-based permissions
- Column-level masking
- Data lineage tracking
- Versioned datasets for auditability
Governance is moving from reactive enforcement to embedded design.
Cost and Performance Optimization
Cloud warehouses offer elastic scale, but uncontrolled workloads drive cost volatility. Organizations are implementing workload isolation, query monitoring, and usage-based governance.
Compute-storage separation allows precise scaling. Teams spin up resources for heavy workloads and scale down when idle. This aligns performance with financial accountability.
The future of data warehousing is not just about storing more data. It is about creating intelligent, governed, and continuously available data systems that support analytics and AI without operational friction.
Powering Your Data Warehouse with Unified Marketing Data
A warehouse only creates value if the right data enters it.
Marketing data rarely arrives clean, structured, or consistent. It is fragmented across ad platforms, CRM systems, ecommerce tools, and analytics environments. Each source uses different schemas, naming conventions, attribution logic, and refresh cycles.
Without a controlled ingestion layer, the warehouse becomes a collection of inconsistent tables.
How Improvado Strengthens the Warehouse Layer
Improvado operates as an automated ELT layer purpose-built for marketing data. It connects to 1,000+ marketing, sales, and revenue platforms through maintained API connectors.
The platform:
- Extracts data on automated refresh schedules
- Standardizes schemas across channels
- Aligns naming conventions and campaign hierarchies
- Normalizes currencies and timezones
- Resolves identifiers across platforms
- Applies transformations directly inside your warehouse
Data is delivered into Snowflake, BigQuery, Redshift, or other DBMS environments as analysis-ready datasets. Governance rules and metric definitions are enforced before reporting begins.
The AI Agent allows teams to define transformations and validations in plain English, reducing dependency on engineering resources.
The warehouse provides storage and compute. Improvado ensures consistency, structure, and reliability at the ingestion layer.
Conclusion
Data warehouse solutions are foundational to modern business success. By centralizing your information, you enable faster reporting, deeper insights, and more intelligent decision-making across your entire organization.
Choosing the right platform—whether it's BigQuery, Snowflake, Redshift, or another—depends on your unique needs. Carefully evaluate your data volume, use cases, budget, and technical resources.
However, remember that the warehouse itself is only half the battle. Populating it with clean, reliable, and timely data is the critical next step. This is where automated platforms like Improvado become non-negotiable, freeing your team to focus on what truly matters: extracting value and driving growth.


