
As organizations operate across fragmented source systems and increasingly push analytics and AI workloads into the warehouse, the bottleneck is rarely data volume — it is inconsistency and lack of standardized structure. Precision in how data is cleaned, modeled, and validated determines the accuracy of downstream analysis and the reliability of automated decision systems.
This guide examines the practical mechanics of enterprise-grade data preparation. We'll focus on frameworks and workflows used in modern analytics environments to eliminate rework, reduce error surfaces, and enable fast, repeatable insight generation without sacrificing rigor.
Key Takeaways:
- Foundation of Analytics: Data preparation is the critical process of cleaning, structuring, and enriching raw data to make it suitable for analysis and machine learning, directly impacting the reliability of all subsequent insights.
- A Multi-Step Process: The process involves distinct, sequential steps: Data Discovery, Collection, Cleansing, Transformation, Enrichment, Validation, and Loading. Each step is vital for ensuring data quality.
- Major Business Impact: Effective data preparation leads to enhanced data quality, faster decision-making, the enablement of advanced AI/ML models, better regulatory compliance, and a higher return on investment for analytics projects.
- Automation is Key: Manual data preparation is a significant bottleneck, consuming up to 80% of an analyst's time. Automated platforms like Improvado are essential for scaling analytics, reducing errors, and freeing up teams to focus on generating insights.
Quick answer
Data preparation is the comprehensive process of finding, cleaning, transforming, and structuring raw data into a clean, consistent, and analysis-ready format. It is the foundational stage of any data-driven workflow, ensuring that data used for analysis, reporting, and model training is accurate, complete, and relevant.
What Is Data Preparation? A Foundational Overview
Data preparation is the comprehensive process of finding, cleaning, transforming, and structuring raw data into a clean, consistent, and analysis-ready format. It is the foundational stage of any data-driven workflow, ensuring that the data used for analysis, reporting, and model training is accurate, complete, and relevant.
Defining Data Preparation vs. Data Cleansing vs. Data Transformation
While often used interchangeably, these terms represent distinct phases within the broader data preparation workflow:
- Data Preparation: The overarching process that encompasses all activities required to get raw data ready for analysis. It includes cleansing and transformation as sub-processes.
- Data Cleansing: The specific task of identifying and correcting or removing errors, duplications, and inconsistencies in a dataset. This includes fixing typos, handling missing values, and removing duplicate records.
- Data Transformation: The process of converting data from one format or structure to another. This can involve normalizing data, aggregating fields, creating new calculated features (feature engineering), and harmonizing data from different sources into a unified schema.
The Role of Data Prep in the Analytics Lifecycle
Data preparation sits between data collection and data analysis or visualization. It is the bridge that turns a chaotic collection of raw information into a structured asset. Without this bridge, data scientists and analysts would spend the vast majority of their time wrestling with data issues rather than uncovering insights.
A robust data preparation process makes the entire analytics lifecycle more efficient, repeatable, and trustworthy.
Who Is Responsible for Data Preparation?
Historically, data preparation was the domain of IT and data engineers who wrote complex scripts to process data. Today, the responsibility is more distributed, involving a range of roles:
- Data Engineers: Build and maintain the large-scale data pipelines and infrastructure for data preparation.
- Data Scientists: Often perform sophisticated data preparation tasks, including feature engineering, to prepare data for machine learning models.
- Business Analysts: Use self-service tools to prepare smaller, specific datasets for reporting and BI dashboards.
- Marketing Analysts: Focus on preparing and harmonizing data from various marketing platforms (CRMs, ad networks, analytics tools) to measure campaign performance.
Why Data Preparation is Non-Negotiable for Business Success
Data preparation is not just a technical prerequisite; it's a strategic business imperative. Investing in a solid data preparation process yields significant returns that impact the entire organization.
Enhances Data Quality and Reliability
This is the most direct benefit. According to Gartner, poor data quality costs organizations an average of $12.9 million annually.
A structured data preparation process systematically eliminates errors, inconsistencies, and duplicates. This builds a foundation of trust in your data, ensuring that strategic decisions are based on accurate, reliable information rather than guesswork.
Accelerates Time-to-Insight and Decision-Making Speed
Manual data preparation is a notorious bottleneck. By standardizing and automating the process, organizations can dramatically reduce the time it takes to get from raw data to actionable insight.
Well-prepared data streamlines the analysis process, allowing for quicker reporting and faster, more confident decision-making.
"Improvado helped us gain full control over our marketing data globally. Previously, we couldn't get reports from different locations on time and in the same format, so it took days to standardize them. Today, we can finally build any report we want in minutes due to the vast number of data connectors and rich granularity provided by Improvado.
Now, we don't have to involve our technical team in the reporting part at all. Improvado saves about 90 hours per week and allows us to focus on data analysis rather than routine data aggregation, normalization, and formatting."
Read the full case study →

Unlocks Advanced Analytics and Machine Learning
Machine learning and AI models are highly sensitive to the quality and structure of the input data. Properly prepared, cleaned, and feature-engineered data is an absolute requirement for building accurate predictive models.
As enterprises increasingly prioritize AI initiatives, the need for high-quality, well-structured data to fuel these technologies becomes paramount.
Ensures Data Governance and Regulatory Compliance
With regulations like GDPR and CCPA, how data is handled has serious legal and financial implications. A formal data preparation process is a core component of strong data governance.
It provides a clear audit trail (data lineage), standardizes data handling procedures, and makes it easier to manage sensitive customer data, ensuring compliance across multiple jurisdictions.
Maximizes ROI on Analytics and Marketing Investments
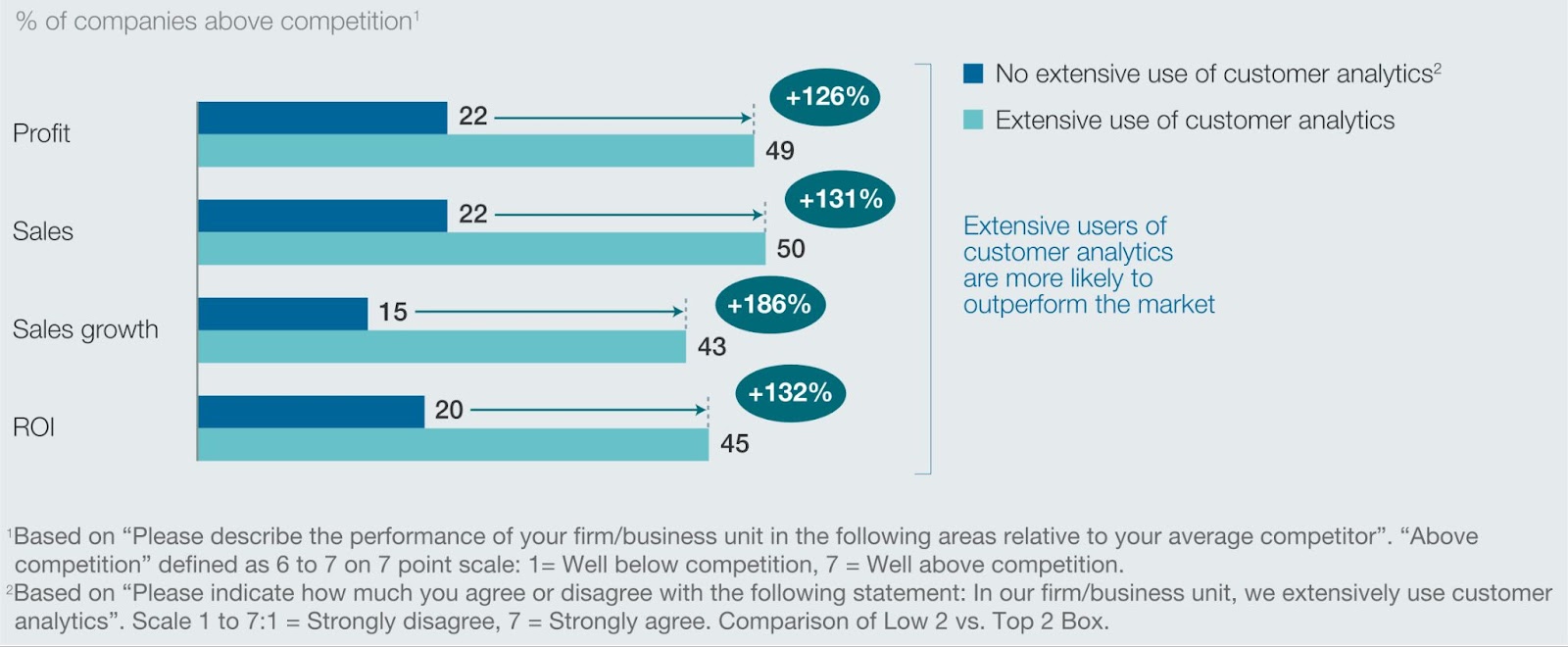
By providing a clear, accurate, and unified view of performance, well-prepared data enables more effective budget allocation and strategy optimization. A report by McKinsey found that data-driven organizations are 23 times more likely to acquire customers and 19 times more likely to be profitable.
This level of performance is impossible without a solid data preparation foundation.
The 7 Core Steps of the Data Preparation Process
A structured approach to data preparation is crucial for consistency and quality. While specifics can vary, the process generally follows these seven core steps.
Step 1: Data Discovery and Profiling
Before you can clean data, you must understand it. This initial step involves exploring the raw data to understand its structure, content, quality, and relationships.
Data profiling tools can be used to generate summary statistics, identify data types, find value distributions, and flag potential issues like an unexpectedly high number of null values.
Step 2: Data Collection and Integration
Here, you gather data from all relevant sources, which could include CRM systems, marketing automation platforms, social media, web analytics tools, databases, and flat files.
The challenge is integrating these diverse datasets into a cohesive whole. This is where the right data integration tools and ETL (Extract, Transform, Load) platforms are critical for consolidating data efficiently and reliably.
Step 3: Data Cleansing and Deduplication
This is where the "dirty work" happens. Raw data is often riddled with errors. The cleansing step focuses on identifying and resolving these issues:
- Handling Missing Values: Deciding whether to delete records with missing data, or impute (estimate) the missing values based on other data points.
- Correcting Errors: Fixing structural errors like typos, incorrect capitalization, or inconsistent formatting (e.g., "CA" vs. "California").
- Removing Duplicates: Identifying and merging or deleting duplicate records to ensure each entity (like a customer) is represented only once.
Step 4: Data Transformation and Structuring
Once the data is clean, it must be transformed into the proper structure for analysis. This is a critical part of the ETL process and involves several activities:
- Normalization: Scaling numerical data to a standard range (e.g., 0 to 1) to prevent variables with larger scales from dominating analyses or machine learning models.
- Aggregation: Summarizing data at a higher level, such as calculating total monthly sales from daily transaction records.
- Feature Engineering: Creating new, more insightful variables from existing ones. For example, calculating a "customer lifetime value" from purchase history and engagement data.
- Harmonization: Reconciling schematic differences across different data sources, such as mapping "Cost" from one platform and "Spend" from another to a single, standardized "Marketing Spend" metric.
Step 5: Data Enrichment
Data enrichment involves enhancing your existing dataset by appending data from external sources. This adds valuable context and depth to your analysis.
Examples include adding demographic data to customer profiles, incorporating weather data to analyze retail sales, or including industry benchmarks for performance comparison.
Step 6: Data Validation and Quality Assurance
Before the data is made available for analysis, it must be validated. This step involves running automated checks and manual reviews to ensure it meets predefined quality standards.
This can include checking for anomalies, outliers, and unexpected patterns. It serves as a final quality gate, confirming that the preparation process was successful and the data is trustworthy.
Step 7: Loading and Storing the Prepared Data
Finally, the clean, transformed, and validated data is loaded into its destination system. This is typically a centralized repository like a data warehouse or data lake, from which it can be easily accessed by BI tools, analytics platforms, and data science teams for analysis and reporting.
Common Data Preparation Challenges and How to Overcome Them
While the steps are straightforward in theory, executing them in a real-world enterprise environment presents several significant challenges.
Dealing with High Volume and Variety of Data Sources
An average enterprise-grade marketing team operates with 100+ martech solutions and marketing and advertising platforms. Each data source has its own format, schema, and access method. Manually connecting to and managing these sources is not scalable.
Solution: Use an automated data integration platform that has pre-built connectors for all your key sources, abstracting away the complexity of API management and data extraction.
Improvado streamlines the entire process with pre-built data connectors and marketing-specific transformation recipes. This dramatically reduces setup time, minimizes manual errors, and accelerates the path from raw data to trustworthy insights.
“Once the data's flowing and our recipes are good to go—it's just set it and forget it. We never have issues with data timing out or not populating in GBQ. We only go into the platform now to handle a backend refresh if naming conventions change or something. That's it.”
"With Improvado, we now trust the data. If anything is wrong, it’s how someone on the team is viewing it, not the data itself. It’s 99.9% accurate.”

Ensuring Data Consistency and Accuracy Across Silos
Data silos are the enemy of a single source of truth. The same metric, for example, a customer, might be defined differently in the CRM, the marketing platform, and the finance system. Reconciling these differences is a major headache.
Solution: Implement a robust data governance framework with a centralized data dictionary. Use an automated transformation tool to enforce a master data model, ensuring all data is harmonized to a consistent standard.
The Time-Consuming Nature of Manual Processes
Studies consistently show that data scientists and analysts spend up to 80% of their time on data preparation and management, leaving only 20% for actual analysis. This manual effort is slow, prone to human error, and a massive drain on expensive resources.
Solution: Automate every repetitive task in the data preparation workflow. Automated cleansing rules, transformation logic, and validation checks can reduce preparation time from weeks to hours, freeing up your team to focus on value-added activities.
Before Improvado, preparing reports at Signal Theory was a labor-intensive process, often taking four hours or more per report. Switching to Improvado reduced that time by over 80%, making reporting significantly more efficient and far less stressful.
"Reports that used to take hours now only take about 30 minutes. We're reporting for significantly more clients, even though it is only being handled by a single person. That's been huge for us.”

Lack of Standardized Processes and Data Governance
Without a defined process, data preparation becomes an ad-hoc, wild west activity. Different analysts prepare data in different ways, leading to inconsistent and non-reproducible results. This undermines trust in the data across the organization.
Solution: Document a standardized data preparation workflow and implement tools that enforce it. Utilize features like data lineage tracking to see exactly how data has been transformed from source to destination, providing transparency and accountability.
Choosing Your Data Preparation Tools: A Comparative Look
The toolset you choose for data preparation has a massive impact on your efficiency, scalability, and the quality of your results. The options generally fall into three categories.
Manual Preparation with Spreadsheets (Excel, Google Sheets)
For very small, one-off tasks, spreadsheets are a familiar and accessible tool. However, they lack scalability, version control, and automation capabilities. Spreadsheets are highly prone to manual error and become unmanageable with even moderately complex datasets.
Code-Based Preparation (Python, R)
Using programming languages like Python (with libraries like Pandas) or R provides immense power and flexibility.
This approach is highly customizable and can handle complex transformations. The downside is that it requires specialized programming skills, is time-consuming to develop and maintain, and can create dependencies on specific individuals.
Self-Service Data Prep & Automated ETL/ELT Platforms like Improvado
This modern category of tools is designed to address the shortcomings of manual and code-based methods. They provide a visual, user-friendly interface to build data pipelines, automate transformations, and manage the entire preparation process without writing code. Platforms like Improvado are purpose-built for marketing analytics, offering pre-built connectors and transformation models that drastically accelerate the process.
Comparison: Manual vs. Code-Based vs. Automated Data Preparation
| Aspect | Manual (Spreadsheets) | Code-Based (Python/R) | Automated Platform (Improvado) |
|---|---|---|---|
| Speed and Efficiency | Very Slow | Slow to develop, fast to execute | Very Fast (Setup in hours) |
| Scalability | Low (Fails with large data) | High (Dependent on infrastructure) | Very High (Cloud-native architecture) |
| Technical Skill Required | Low (Basic spreadsheet skills) | High (Expert programming skills) | Low (No code required) |
| Accuracy and Consistency | Low (Prone to human error) | High (If code is correct) | Very High (Standardized, repeatable logic) |
| Maintenance Cost | Low (Initial cost), High (Time cost) | High (Requires ongoing developer time) | Low (Managed platform, no maintenance) |
| Data Governance and Lineage | None | Manual (Must be coded in) | Built-in and Automated |
| Collaboration | Difficult (Version control issues) | Moderate (Via Git, etc.) | High (Centralized platform) |
| Best For | Small, one-off ad-hoc tasks | Highly custom, complex data science projects | Enterprise-scale, repeatable analytics workflows |
Data Preparation in Practice: Key Use Cases
The impact of excellent data preparation is felt across numerous business functions. Here are a few key applications.
For Business Intelligence and Reporting
BI dashboards are the face of data for most business users. Data preparation ensures that the underlying data feeding these dashboards is clean, consistent, and up-to-date.
This involves aggregating data from various operational systems into a format suitable for creating compelling and accurate KPI dashboards. Effective preparation is the engine behind reliable reporting automation.
For Marketing Analytics and Attribution
Marketing teams grapple with data from countless channels: social media, email, CRM, paid ads, web analytics, and more. Data preparation is essential for creating a unified view of the customer journey. It involves harmonizing campaign naming conventions, standardizing metrics (e.g., clicks, impressions), and stitching together user interactions across platforms to enable accurate marketing attribution and performance measurement.
For Machine Learning and Predictive Modeling
As mentioned, ML models require meticulously prepared data. This use case involves more advanced techniques like one-hot encoding for categorical variables, handling class imbalance, and sophisticated feature engineering to create signals that improve model accuracy. The quality of data preparation can be the difference between a highly predictive model and one that fails completely.
Data Preparation Best Practices for Enterprise Teams
To build a scalable and sustainable data preparation capability, follow these enterprise-level best practices.
- Establish Clear Data Governance Policies: Define ownership, standards, and rules for your key data assets. A central data dictionary ensures everyone speaks the same language.
- Automate Everything Possible: Identify repetitive data preparation tasks and automate them. This reduces errors, saves time, and ensures consistency.
- Document Processes and Maintain Data Lineage: Keep detailed records of your data transformation rules. Use tools that provide automated data lineage so you can trace any data point back to its source.
- Implement a Feedback Loop for Continuous Improvement: Create a process for data consumers (analysts, business users) to report data quality issues. Use this feedback to refine and improve your preparation workflows over time.
- Foster Collaboration Between IT and Business Teams: Data preparation is most successful when technical teams who manage the infrastructure and business teams who understand the data context work together closely.
How Improvado Streamlines the Data Preparation Process
Improvado provides a robust, end-to-end marketing analytics platform specifically designed to eliminate the complexities of data preparation for enterprise companies. By automating the entire workflow, Improvado empowers teams to focus on analysis rather than data wrangling.
Automated Data Collection from 1,000+ Sources
Improvado offers a vast library of pre-built connectors to all major marketing, sales, and analytics platforms. The platform supports offline and online sources, flat data ingestion, niche tools, and builds custom connectors on request.
This eliminates the need for manual data extraction or building fragile custom API integrations. The platform handles authentication, pagination, and API changes automatically, ensuring a reliable flow of data.
AI-Powered Data Transformation and Harmonization
The platform's strength lies in its intelligent transformation layer that includes:
- Transform & Model Capabilities: Improvado centralizes data from over 500 sources and applies consistent taxonomies, rules, and business logic at scale. Teams can create reusable, modular transformation workflows that ensure uniform data structures across brands, regions, and campaigns — without heavy reliance on engineering teams.
- AI-Powered Transformation Agents: With Improvado’s AI Agent for Transformation, repetitive tasks like mapping, normalization, and enrichment are automated. The AI suggests transformations, detects anomalies, and flags discrepancies, reducing manual workload and accelerating time-to-value.
- Built-In Governance and Security: The platform includes strict version control, audit trails, and data lineage tracking. These features give enterprise teams confidence that transformed datasets are accurate, compliant, and secure — critical for scaling operations across multiple markets and regulatory environments.
Seamless Integration with Your Data Warehouse and BI Tools
Improvado isn't a black box. It delivers analysis-ready data directly to your preferred destination, whether it's a data warehouse like BigQuery, Snowflake, or Redshift, or a BI tool like Tableau or Power BI. This flexibility ensures that your prepared data fits seamlessly into your existing analytics stack.
For teams looking to centralize governance and keep intelligence inside their own environment, Improvado can also run directly on top of your data warehouse. This warehouse-native option lets you standardize, model, and transform marketing data in place, maintaining full ownership, security, and transparency while scaling marketing insights 5-10× faster.
The Future of Data Preparation: AI and Intelligent Automation
The field of data preparation is evolving rapidly, driven by advancements in artificial intelligence and automation. The future is less about manual intervention and more about intelligent systems that assist and augment the analyst.
The Rise of Augmented Data Preparation
Augmented data preparation uses machine learning to recommend transformations, data cleansing rules, and enrichment opportunities. These systems can analyze a dataset, identify potential quality issues, and suggest the best course of action, significantly accelerating the process and making it more accessible to less technical users.
Predictive Data Quality and Cleansing
Instead of reacting to data quality issues, future systems will predict them. By analyzing historical data patterns, AI models will be able to flag potential errors as data is ingested, allowing for proactive correction before the bad data ever enters the analytics environment.
The Shift Towards Real-Time Data Preparation
As the demand for real-time insights grows, batch-based data preparation processes are becoming insufficient. The future lies in streaming data preparation, where data is cleaned, transformed, and validated on the fly as it is generated. This enables true real-time analytics for use cases like fraud detection, operational monitoring, and instant campaign optimization.
Conclusion
Without a rigorous, efficient, and scalable process for transforming raw data into a trustworthy asset, any investment in advanced analytics, business intelligence, or machine learning is fundamentally undermined.
Improvado provides the foundation required to operationalize data at scale: standardizing schemas, enforcing naming conventions, modeling business entities, and automating validation directly within your warehouse environment. Instead of stitching tools together or relying on brittle manual workflows, teams gain a governed, repeatable data pipeline built for enterprise analytics and AI-driven execution.
Request a demo and see how Improvado accelerates data preparation and insight delivery across your organization.


