
Enterprise marketing teams now operate inside sprawling technology ecosystems. The average organization uses close to 100 marketing and analytics tools, spanning ad platforms, CRMs, analytics suites, data warehouses, finance systems, and other platforms.
Each system produces valuable data. Few are designed to work together. The result is fragmented reporting, inconsistent metrics, slow analysis, and decision-making built on partial truth.
This guide explains how modern data integration solutions address this complexity. You’ll learn the core integration models, architectural patterns, and governance requirements needed to build a reliable data foundation.
Key Takeaways
- Enterprise data integration connects and synchronizes data across cloud, on-premise, and hybrid systems to eliminate silos and improve decision-making.
- Integration techniques like ETL, ELT, APIs, data virtualization, and CDC enable scalable, real-time data pipelines across complex environments.
- Companies with advanced integration practices make decisions 2.5x faster and achieve 30–50% higher operational efficiency.
- Strong integration frameworks improve data quality, consistency, governance, and compliance across all business units.
- The future of integration is AI-driven and metadata-based, leveraging data fabric architectures, automation, and DataOps principles.
- Effective data integration strategies create unified data ecosystems that power analytics, machine learning, and digital transformation initiatives.
Quick answer
Data integration solutions connect and synchronize data across cloud, on-premise, and hybrid systems to eliminate silos and improve decision-making. They establish standardized pipelines, shared data models, and governed data flows that collect information once, transform it consistently, and make it available to every team, creating a single trusted data foundation for reporting, automation, and AI.
What Is Meant by Enterprise Data Integration?
Enterprise data integration is the practice of connecting all core business systems so data moves reliably across the organization. It links marketing platforms, analytics tools, CRMs, data warehouses, finance systems, and operational applications into a coordinated data environment.
Unlike point-to-point integrations that solve isolated needs, enterprise integration establishes standardized pipelines, shared data models, and governed data flows. Information is collected once, transformed consistently, and made available to every team that needs it.
This creates a single, trusted data foundation that supports reporting, automation, AI, and cross-department decision-making at scale.
Is Data Integration the Same as ETL?
This is one of the most common misconceptions in data management – the terms are related but not interchangeable. ETL is a specific technique within the broader discipline of data integration.
Think of data integration as the comprehensive objective, while ETL is one method for achieving that objective.
A comprehensive enterprise data integration strategy typically employs multiple techniques depending on specific requirements. A marketing team might use
- ETL to consolidate advertising platform data into a data warehouse for historical analysis,
- API integration to sync customer data between their CRM and marketing automation platform,
- And streaming integration to capture real-time website behavior for immediate personalization.
Why Is Data Integration Needed in an Enterprise?
Enterprise data environments are inherently fragmented. Marketing platforms, CRM systems, analytics tools, finance software, and operational applications all generate critical information. Most of these systems are built independently. Without integration, data remains isolated, definitions drift, and teams operate on partial views of reality.
Data integration addresses this fragmentation by creating consistent, automated data flows across the organization.
Eliminating Data Silos and Improving Accessibility
Data silos form when teams store and manage data inside disconnected tools. Marketing holds engagement data in ad platforms. Sales manages pipeline data in the CRM. Finance tracks revenue in billing systems. Each team sees only part of the customer and business picture.
Integration pipelines consolidate these datasets into shared repositories such as data warehouses. This allows cross-functional teams to access the same standardized data, align reporting, and collaborate using a single source of truth. Without this, enterprise reporting remains slow, inconsistent, and difficult to scale.
ASUS needed a centralized platform to consolidate global marketing data and deliver comprehensive dashboards and reports for stakeholders.
Improvado, a marketing-focused enterprise analytics solution, seamlessly integrated all of ASUS’s marketing data into a managed BigQuery instance. The solution established a reliable data pipeline for seamless data flow between deployed and in-house solutions.
"Improvado helped us gain full control over our marketing data globally. Previously, we couldn't get reports from different locations on time and in the same format, so it took days to standardize them. Today, we can finally build any report we want in minutes due to the vast number of data connectors and rich granularity provided by Improvado.
Now, we don't have to involve our technical team in the reporting part at all. Improvado saves about 90 hours per week and allows us to focus on data analysis rather than routine data aggregation, normalization, and formatting."

Enabling Real-Time Decision-Making
Modern business decisions require timely data. Campaign performance, inventory levels, customer behavior, and revenue signals change continuously. When data is updated manually or batched infrequently, teams act on outdated information.
Data integration automates ingestion and synchronization across systems. This supports near real-time analytics, rapid performance monitoring, and faster response to market changes. For marketing teams, this directly impacts budget pacing, campaign optimization, and customer engagement strategies.
Before Improvado, preparing reports at Signal Theory was a labor-intensive process, often taking four hours or more per report. Switching to Improvado reduced that time by over 80%, making reporting significantly more efficient.
"Reports that used to take hours now only take about 30 minutes. We're reporting for significantly more clients, even though it is only being handled by a single person. That's been huge for us.”

Improving Data Quality and Consistency
Disconnected systems often contain conflicting records. Customer profiles differ across tools. Metric definitions vary by platform. Manual reconciliation introduces additional errors.
Integration platforms apply standardized schemas, transformation logic, and validation rules to incoming data. This ensures consistent naming, accurate records, and aligned metric definitions across all systems. High-quality data becomes the default state, not an exception.
Before Booyah Advertising implemented Improvado, their analytics team struggled with fragmented data architecture and frequent accuracy issues. Entire days of data were missing, duplicates distorted performance metrics, and aggregation across over 100 clients required extensive manual reconciliation.
After the migration, Booyah realized 99.9% data accuracy and cut daily budget-pacing updates from hours to 10-30 minutes. Improvado’s unified pipelines, normalization logic, and real-time refresh capability gave the agency full visibility and control over multi-source data (15–20 feeds per client).
“We never have issues with data timing out or not populating in GBQ. We only go into the platform now to handle a backend refresh if naming conventions change or something. That's it.
With Improvado, we now trust the data. If anything is wrong, it’s how someone on the team is viewing it, not the data itself. It’s 99.9% accurate.”

Accelerating Digital Transformation
Enterprises continue adopting cloud platforms, AI tools, and advanced analytics solutions. These technologies depend on reliable, unified data to deliver value.
Data integration provides the foundation that allows new systems to plug into existing data environments quickly. It enables scalable analytics, automation, and AI-driven decision-making without rebuilding data pipelines for each new initiative.
In practice, enterprise integration is not just about moving data. It is about making data usable at scale.
Data Integration Methods and Techniques
Enterprises have multiple approaches to implementing data integration, each suited to different use cases, technical requirements, and organizational maturity levels.
ETL (Extract, Transform, Load)
ETL remains one of the most widely adopted data integration techniques. The process involves extracting data from source systems, transforming it to match the target schema and business rules, then loading it into a destination repository.
Modern ETL platforms have evolved significantly from traditional batch-oriented tools. Today's solutions support near real-time processing, cloud-native architectures, and low-code development environments that accelerate implementation.
When to Use ETL
- Building and maintaining data warehouses for historical analysis
- Consolidating data from legacy systems with complex transformation requirements
- Processing large volumes of data in scheduled batches
- Scenarios where data quality and validation are critical before loading
ELT (Extract, Load, Transform)
ELT reverses the traditional ETL sequence by loading raw data into the target system first, then performing transformations using the processing power of modern cloud data platforms. This approach has gained popularity with the rise of cloud data warehouses like Snowflake, BigQuery, and Redshift, which offer massive computational capabilities.
Advantages of ELT
- Faster initial data loading since transformation happens after ingestion
- Greater flexibility to create multiple transformation views from the same raw data
- Scalability leveraging cloud platform computational resources
- Simplified data pipelines with fewer intermediate steps
API-Based Integration
Application Programming Interfaces (APIs) enable real-time, bidirectional data exchange between systems. RESTful APIs have become the standard for modern cloud applications, allowing systems to request and receive data on-demand rather than through scheduled batch processes.
For marketing operations, API-based integration is essential for connecting advertising platforms, CRM systems, and analytics tools. Solutions like marketing data pipelines leverage APIs to create continuous data flows that power real-time reporting and optimization.
Data Virtualization
Data virtualization provides a unified view of data across multiple sources without physically moving or replicating it. This approach creates a logical abstraction layer that queries data from source systems in real-time, presenting it as if it were in a single location.
Data Virtualization Use Cases
- Rapid development of analytics and reporting without ETL development
- Scenarios where data cannot be moved due to regulatory or security constraints
- Exploratory analytics and prototyping before committing to physical integration
- Supplementing data warehouses with real-time data from operational systems
Change Data Capture (CDC)
CDC techniques identify and capture only the data that has changed in source systems since the last extraction, dramatically reducing processing overhead and enabling near real-time synchronization.
Modern CDC approaches use database transaction logs, timestamps, or triggers to detect changes efficiently.
Data Integration Methods and Techniques: Comparison Table
| Approach | Best Use Cases | Key Decision Factors |
|---|---|---|
| ETL | Standardized cross-channel reporting, historical performance analysis, and attribution dashboards. | Works best when data models are well-defined, transformations are stable, and batch updates are acceptable. |
| ELT | Large-scale customer journey analysis, behavioral segmentation, and warehouse-native analytics. | Best if you have a modern cloud data warehouse and want flexibility to re-transform raw data as needs evolve. |
| API-Based Integration | Frequent syncing of ad platform metrics, campaign pacing dashboards, and near-real-time reporting. | Suitable when platform APIs are reliable, data volumes are moderate, and real-time freshness matters. |
| Data Virtualization | Cross-department analysis when marketing data cannot be physically moved due to governance or security constraints. | Fits enterprises with strict data residency policies and existing distributed data systems. |
| Change Data Capture (CDC) | Keeping CRM, ecommerce, and customer event data continuously updated for personalization and lifecycle marketing. | Ideal when low-latency customer data updates are required without reprocessing full datasets. |
Enterprise Data Integration Platforms and Tools
The enterprise data integration landscape has evolved dramatically, with solutions ranging from traditional ETL tools to modern cloud-native platforms and iPaaS (Integration Platform as a Service) offerings.
Traditional Enterprise Integration Platforms
Established vendors like Informatica, IBM DataStage, and Oracle Data Integrator have long dominated the enterprise integration space. These platforms offer comprehensive capabilities for batch processing, data quality, and complex transformations, particularly suited for large-scale on-premise data warehouse projects.
Cloud-Native Integration Platforms
Modern cloud-native platforms are designed specifically for cloud and hybrid environments.
| Platform Category | Key Capabilities | Ideal Use Cases |
|---|---|---|
| Cloud ETL Platforms | Pre-built connectors, elastic scaling, pay-per-use pricing | Cloud data warehouse integration, SaaS application consolidation |
| iPaaS Solutions | Low-code and no-code development, API management, workflow orchestration | Application integration, business process automation |
| Data Fabric Platforms | Metadata-driven integration, AI-powered data discovery, unified governance | Complex hybrid environments, multi-cloud strategies |
| Reverse ETL | Data warehouse to operational system sync, audience activation | Marketing automation, CRM enrichment, operational analytics |
Specialized Marketing Data Integration
Marketing teams face unique data integration challenges. Specialized solutions like Improvado address these needs with pre-built connectors, marketing-specific data models, and automated campaign performance consolidation.
General-purpose integration tools are not built for marketing data complexity. Advertising platforms use different schemas. Metrics have inconsistent definitions. Campaign structures vary by channel. Attribution logic differs across tools. Improvado is designed specifically to solve these problems.
Improvado provides a marketing-focused data integration layer that automates ingestion, transformation, and governance before data reaches analytics or BI systems.
Key capabilities include:
- Pre-built connectors to hundreds of ad platforms, analytics tools, CRMs, ecommerce systems, and revenue sources
- Automated data ingestion with scheduled refreshes and API change handling
- Marketing-specific data models that standardize campaigns, creatives, audiences, and conversions
- Metric and naming normalization to align KPIs across platforms
- Currency, timezone, and attribution standardization
- Identity and entity mapping to connect campaigns, users, and revenue
- Data validation and governance rules to detect anomalies and enforce consistency
- Delivery of analysis-ready datasets to data warehouses, BI tools, and native dashboards
This removes manual data preparation from marketing operations. Teams get consistent, trusted data for reporting, attribution, optimization, and AI-driven insights.
Best Practices for Enterprise Data Integration Strategy
Successful enterprise data integration requires more than selecting the right technology – it demands strategic planning, organizational alignment, and disciplined execution.
Start with Business Outcomes, Not Technology
The most common pitfall in data integration initiatives is starting with technology selection rather than business objectives. Before evaluating platforms, define clear success criteria:
- What business decisions will integrated data enable?
- What processes will become more efficient?
- What customer experiences will improve?
Create specific, measurable use cases that justify integration investment. For marketing teams, this might include consolidating campaign performance across all paid channels, creating unified customer profiles from CRM and engagement data, or enabling real-time marketing attribution across touchpoints.
Implement a Hybrid Integration Architecture
Most enterprises operate in hybrid environments where critical legacy systems coexist with modern cloud applications. Rather than pursuing a "rip and replace" strategy, design integration architectures that accommodate both worlds:
- Cloud-based integration hubs that connect both cloud and on-premise sources
- API gateways that provide standardized interfaces to legacy systems
- Hybrid data storage strategies that keep sensitive data on-premise while leveraging cloud scalability for analytics
- Multi-cloud integration capabilities for organizations using multiple cloud providers
Implement Data Validation at the Point of Entry
The most effective way to keep bad data out is to prevent it from ever entering your systems. Implement strict validation rules in your forms, applications, and data intake processes.
For example, ensure email fields accept only valid email formats or that state fields use a standardized two-letter abbreviation. This proactive approach significantly reduces the need for reactive data cleaning down the line.
Embrace Low-Code and No-Code Capabilities
Modern integration platforms increasingly offer visual, drag-and-drop development environments that enable business analysts and citizen developers to create integrations without extensive coding.
This democratization of integration development accelerates delivery, reduces IT bottlenecks, and empowers business users who understand the data requirements.
However, balance self-service capabilities with governance. Implement approval workflows, testing requirements, and architectural standards that prevent ungoverned sprawl of integrations.
Design for Real-Time Where It Matters
Not all data integration needs to be real-time. Batch processing remains cost-effective and appropriate for historical analysis, reporting, and scenarios where sub-minute latency isn't required.
Reserve real-time integration for use cases that genuinely benefit from immediate data availability – fraud detection, inventory management, customer service interactions, or marketing campaign optimization.
Plan for Scalability from Day One
Data volumes, source system counts, and user populations will grow. Design integration architectures that scale gracefully:
- Use cloud-native platforms that scale elastically rather than requiring upfront capacity planning
- Implement modular, reusable integration components rather than hardcoded point-to-point connections
- Leverage pre-built connectors for common applications rather than building custom integrations
- Design data models that accommodate new sources without requiring wholesale restructuring
Overcoming Enterprise Data Integration Challenges
Despite its clear benefits, enterprise data integration presents significant challenges that organizations must navigate successfully.
Managing Integration Complexity
Large enterprises often operate hundreds of systems that require data connectivity. Without a structured integration strategy, teams build point-to-point connections for each new tool. Over time, this creates a fragile web of dependencies that is difficult to maintain, monitor, or scale.
Solution: Adopt a hub-and-spoke integration architecture where all systems connect through a central data layer rather than directly to each other.
In marketing and revenue environments, platforms like Improvado serve as this integration hub. It centralizes data ingestion from hundreds of tools, applies standardized transformations and governance, and distributes clean data to warehouses, BI tools, and downstream applications.
This replaces brittle point-to-point pipelines with a single, managed integration layer that scales as new platforms are added.
Addressing Security and Compliance Concerns
Integration necessarily involves moving sensitive data between systems, creating potential security vulnerabilities and compliance risks. Data in transit requires encryption, systems need robust authentication, and access controls must be consistently enforced.
Solution: Implement comprehensive security frameworks including:
- End-to-end encryption for data in transit and at rest
- Role-based access controls that enforce least-privilege principles
- Data masking and tokenization for sensitive information
- Comprehensive audit logging of all data access and movement
- Regular security assessments and penetration testing
Handling Data Quality and Inconsistency
Different source systems often have conflicting data definitions, formats, and quality levels. Customer names might be formatted differently across systems, dates might use different formats, or product identifiers might not align.
Solution: Establish enterprise-wide data standards and implement data quality tools that profile, cleanse, and standardize data during integration. Create master data management (MDM) capabilities for critical entities like customers, products, and locations.
Managing Legacy System Integration
Many enterprises run critical business processes on legacy systems that weren't designed for modern integration – mainframes, custom applications, or aging databases with limited connectivity options.
Solution: Use integration middleware that provides adapters for legacy systems, database replication technologies, or API gateways that create modern interfaces to legacy applications. In some cases, consider strategic modernization of the most problematic legacy systems.
Enterprise Data Integration Use Cases Across Industries
Enterprise data integration creates value across every sector. Systems differ by industry. The objective stays the same: connect fragmented data to enable reliable operations, accurate analytics, and faster decisions.
Example 1: Retail and E-commerce
Retailers operate across physical stores, ecommerce platforms, marketplaces, and loyalty programs. Each system captures part of the customer and inventory picture. Without integration, omnichannel experiences become inconsistent and inventory visibility breaks down.
Integration focus
- Synchronizing point-of-sale and online transactions
- Connecting inventory and fulfillment systems
- Unifying customer and loyalty profiles
Business outcome
Accurate stock availability, consistent customer experiences, and improved demand planning. Real-time synchronization reduces overselling and fulfillment errors.
Example 2: Financial Services
Banks manage customer data, transaction systems, risk platforms, and compliance tools. These environments are siloed and tightly regulated. Manual reconciliation slows service and increases operational risk.
Integration focus
- Consolidating account and transaction data
- Linking customer interactions across channels
- Automating data feeds for risk and compliance systems
Business outcome
Full customer visibility for relationship managers, faster fraud detection, and automated regulatory reporting.
Example 3: Healthcare
Healthcare organizations rely on EHRs, lab systems, imaging platforms, and billing tools. When records are disconnected, care coordination suffers and decisions lack context.
Integration focus
- Unifying clinical and operational records
- Connecting patient data across providers
- Aligning clinical and billing systems
Business outcome
Complete patient context at point of care, improved care coordination, and more accurate claims processing.
Example 4: Manufacturing
Manufacturers generate data across ERP systems, production equipment, supply chains, and quality tools. Disconnected systems limit real-time operational insight.
Integration focus
- Linking production, inventory, and supplier systems
- Streaming equipment and sensor data into analytics platforms
- Connecting quality data to production batches
Business outcome
Predictive maintenance, real-time production monitoring, and end-to-end supply chain traceability.
Example 5: Marketing and Advertising
Marketing stacks include ad platforms, analytics tools, CRM systems, and revenue databases. Each reports performance differently. Without integration, ROI and attribution remain incomplete.
Integration focus
- Aligning spend, engagement, conversion, and revenue data
- Standardizing campaign and channel schemas
- Connecting marketing touchpoints to downstream revenue
Business outcome
Accurate attribution, reliable ROI measurement, and faster cross-channel optimization.
The Future of Enterprise Data Integration
Enterprise data integration continues to evolve rapidly, driven by technological advances and changing business requirements.
AI-Powered Integration and Automation
Modern AI-driven integration systems can detect schema changes, recommend mappings, and apply transformations without manual configuration. They monitor data patterns to flag anomalies. They adjust pipeline logic as data volumes and structures evolve. This reduces maintenance overhead and improves data reliability at scale.
Improvado is an example of an AI-powered marketing data integration platform already operating this model in production.
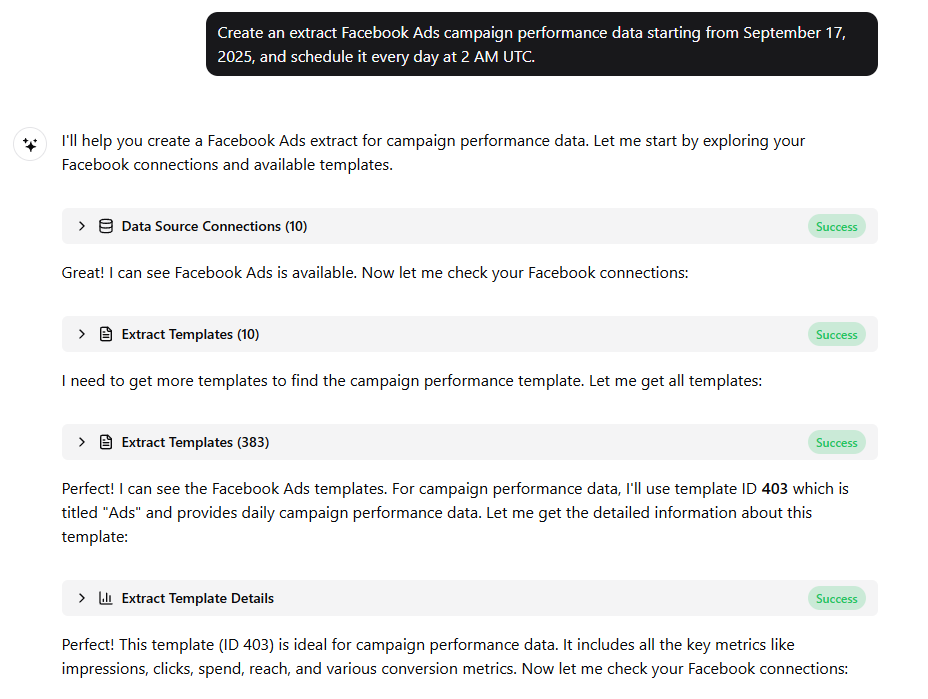
Improvado AI Agent automates both data aggregation and transformation across hundreds of marketing and revenue sources. Instead of manually building pipelines, teams define goals in plain language. The system generates extraction, loading, and transformation logic automatically.
Key AI-powered integration capabilities in Improvado include:
- Automated extraction and loading pipelines that adapt to API and schema changes
- AI-generated transformation logic for cleaning, mapping, and normalizing data
- Reusable transformation recipes that standardize metrics across sources
- Natural-language instructions to create or modify data workflows
- Continuous validation to ensure pipeline and output data integrity
The result is faster integration deployment, lower engineering dependency, and consistently analysis-ready data. AI shifts integration from custom development to automated infrastructure.
The Rise of Data Fabric Architectures
Data fabric represents an emerging architectural approach that uses metadata, semantics, and ML to create intelligent, self-configuring integration layers.
Rather than manually building integrations, data fabric platforms automatically discover data sources, understand relationships, and dynamically create connections based on user needs.
Read our guide to learn more about data fabric and a unified approach to data architecture.
Edge Computing and IoT Integration
Enterprises now collect massive volumes of data from connected devices. Sensors, wearables, retail beacons, and smart equipment generate continuous data streams. Sending all raw data to central systems is expensive and slow.
Edge computing changes this model. Data is filtered, aggregated, and transformed closer to where it is created. Only relevant, structured data is transmitted to central platforms. This reduces bandwidth costs and latency. It also enables real-time decision-making for time-sensitive use cases like dynamic pricing, fraud detection, and inventory monitoring.
Integration architectures must now support both edge and centralized pipelines. This requires flexible ingestion, transformation, and synchronization across distributed environments.
DataOps and Integration as Code
Enterprises now collect massive volumes of data from connected devices. Sensors, wearables, retail beacons, and smart equipment generate continuous data streams. Sending all raw data to central systems is expensive and slow.
Edge computing changes this model. Data is filtered, aggregated, and transformed closer to where it is created. Only relevant, structured data is transmitted to central platforms. This reduces bandwidth costs and latency. It also enables real-time decision-making for time-sensitive use cases like dynamic pricing, fraud detection, and inventory monitoring.
Integration architectures must now support both edge and centralized pipelines. This requires flexible ingestion, transformation, and synchronization across distributed environments.
Privacy-Preserving Integration
Privacy regulations and platform restrictions limit how user-level data can be shared. This forces new approaches to integration and analytics.
Privacy-preserving techniques allow organizations to analyze data without exposing raw records. Common methods include federated learning, differential privacy, and secure data clean rooms. These approaches enable collaboration across partners while maintaining regulatory compliance and customer trust.
Future integration platforms must balance data accessibility with privacy controls. Enterprises that adopt privacy-aware integration architectures will maintain analytical depth without increasing legal or reputational risk.
Conclusion
Enterprise data integration is no longer a backend IT concern. It is the foundation for analytics, automation, and sustainable growth. Without integrated data, reporting remains fragmented, AI initiatives lack reliable inputs, and decision-making slows down. With it, organizations gain consistent metrics, real-time visibility, and the ability to adopt emerging technologies with confidence.
Improvado helps enterprises operationalize this foundation. It aggregates data from hundreds of marketing and revenue systems, standardizes schemas and metrics, applies governance controls, and delivers analysis-ready data to warehouses, BI tools, and AI layers. Teams replace fragile point-to-point integrations with a scalable, managed data fabric built for modern analytics.
If your organization is ready to move from fragmented systems to unified intelligence, schedule a demo with Improvado.


