
ETL and ELT are methods of moving data from one place to another and transforming it along the way. But which one is right for your business?
This post compares ETL and ELT in speed, data retention, scalability, unstructured data management, regulatory compliance, maintenance, and costs. By the end, you should know when to use each method in your data pipeline and why.
Key Takeaways:
- Core Difference: ETL transforms data before loading it into a data warehouse. ELT loads raw data first and transforms it inside the data warehouse.
- ETL is for Compliance: The traditional ETL process is ideal for structured data, on-premises systems, and industries with strict data privacy and compliance needs like healthcare and finance.
- ELT is for Speed & Scale: The modern ELT process leverages the power of cloud data warehouses. It excels with large volumes of unstructured data and the need for real-time analytics.
- Cost & Skills Vary: ETL often requires specialized developers and can have higher upfront costs. ELT relies on more accessible SQL skills and cloud-based, pay-as-you-go pricing models.
What Is ETL? A Deep Dive into Extract, Transform, Load
ETL stands for Extract, Transform, and Load. It has been the standard approach to data integration for decades. It's a linear, structured process designed to ensure data quality and consistency before the data ever reaches its final destination.
Let's break down each step of the ETL process.
The 'Extract' Phase: Gathering Data from Diverse Sources
The first step is to extract data from its original location.
These data sources can be incredibly varied. They might include relational databases like MySQL or PostgreSQL. They could be SaaS applications like Salesforce or Google Ads. Or they could even be flat files like CSVs and spreadsheets.
The goal of this phase is to pull data from these disparate systems into a single staging area for processing. Effective extraction requires robust connectors to handle different APIs and data formats.
The 'Transform' Phase: The Heart of Data Cleansing and Structuring
Data transformation is the defining step of ETL. Once data is in the staging area, it undergoes a series of transformations. This is a critical data governance step.
Transformations can include:
- Cleansing: Fixing inconsistencies, removing duplicates, and handling missing values.
- Standardizing: Ensuring data formats are consistent (e.g., converting all dates to 'YYYY-MM-DD').
- Enriching: Combining data from one source with data from another to add context.
- Aggregating: Summarizing data to a higher level (e.g., calculating daily sales from transactional data).
- Masking: Obscuring sensitive data like PII to comply with privacy regulations.
This transformation stage requires a dedicated processing engine separate from the source and target systems. The logic is often complex and requires specialized data integration tools or custom code.
The 'Load' Phase: Moving Processed Data to the Target System
After transformation, the clean, structured data is loaded into the target system.
Traditionally, this was an on-premises enterprise data warehouse. The loaded data is analytics-ready. Business analysts and data scientists can query it immediately to build reports and dashboards. Because the data is pre-processed, queries are typically fast and efficient.
Common ETL Use Cases and Scenarios
ETL is most effective when data needs to be shaped and validated before it reaches the destination system. Teams choose ETL when governance, data integrity, and analytical consistency matter more than raw speed.
Common ETL use cases and scenarios:
- Legacy and On-Premises System Integration: When source systems cannot accommodate direct raw loads or API connectivity is limited, ETL enforces structure and prepares data for modern platforms.
- Regulated and Sensitive Data Pipelines: In industries like finance, healthcare, and government, ETL is used to anonymize, encrypt, or mask data before storage to ensure compliance and minimize exposure risk.
- Enterprise Reporting and KPI Dashboards: When leadership relies on fixed, audited metrics (for example, revenue, CAC, SLAs), ETL ensures uniform calculations and consistent definitions across all downstream tools.
- Data Quality Enforcement at Ingestion: Use ETL to validate, cleanse, deduplicate, and reconcile data at the entry point, preventing errors and drift from cascading into core systems.
- Mature Data Models and Stable Business Logic: For organizations with established schemas and predictable reporting structures, ETL provides efficient processing without the overhead of late-stage transformation.
- Third-Party System Normalization: ETL harmonizes data from multiple CRMs, ERPs, or marketing platforms that must conform to a single enterprise schema before centralization.
What is ELT? Understanding Extract, Load, Transform
ELT, or Extract, Load, Transform, is a modern alternative to ETL. It flips the last two steps of the process. This change was made possible by the rise of powerful and scalable cloud data warehouses.
ELT leverages the processing power of the target system, offering greater flexibility and speed.
The 'Extract' Phase: A Familiar First Step
Just like ETL, the ELT process begins by extracting data from various sources.
The goal is the same: pull raw data from operational systems and SaaS applications.
However, the philosophy is different. Instead of selective extraction, ELT often involves pulling all available data, structured or unstructured. This creates a complete raw data archive for future use.
The 'Load' Phase: Raw Data Ingestion into Modern Storage
Here is the first major deviation from ETL.
In ELT, the raw, unprocessed data is immediately loaded into a target system. This target is almost always a cloud data warehouse like Amazon Redshift, Google BigQuery, or Snowflake. These platforms are designed to handle massive volumes of data in various formats.
This step is incredibly fast because no complex transformations are happening in transit. It's simply a data copy operation.
The 'Transform' Phase: In-Warehouse Data Modeling
Once the raw data is inside the data warehouse, the transformation happens.
Data engineers and analysts use the immense computational power of the cloud data warehouse to run transformation jobs. They often use SQL or tools like dbt (Data Build Tool) to model the data.
They can create multiple versions of the data: a raw layer, a staging layer, and a final analytics-ready layer. This approach is often called "schema-on-read," as you define the data structure when you query it, not before you load it.
Common ELT Use Cases and Scenarios
ELT is the go-to choice for businesses dealing with big data. It excels with large volumes of semi-structured or unstructured data from sources like IoT devices, clickstreams, and social media.
When speed to insight is critical, ELT allows analysts to access raw data immediately. This flexibility is vital for data exploration and iterative analysis.
Common ELT Use Cases and Scenarios
- Modern Cloud Data Warehouses and Lakehouses: With scalable compute environments like BigQuery, Snowflake, and Databricks, ELT allows teams to perform complex transformations efficiently after loading raw data.
- Rapidly Evolving Metrics and Business Logic: When definitions, attribution models, or KPI frameworks change frequently, ELT supports fast iteration without rebuilding upstream pipelines.
- Advanced Analytics and Machine Learning: Data scientists benefit from raw, detailed datasets for feature engineering, model training, and longitudinal behavior analysis.
- Real-Time or Near-Real-Time Pipelines: ELT allows data to land quickly and be transformed on-demand, supporting live dashboards, streaming use cases, and operational intelligence.
- Blending Large, Diverse Data Sources: ELT simplifies ingestion from many sources before unifying them into a shared analytical model.
- Preserving Full Granularity for Future Use: Organizations often don’t know today which historical fields will matter tomorrow. ELT keeps raw detail intact, enabling retrospection and new analytic paths.
ETL vs ELT: A Head-to-Head Comparison
Understanding the fundamental differences between ETL and ELT is key to making an informed decision. The best choice depends entirely on your specific needs, infrastructure, and data strategy.
This table provides a quick reference comparison of the two approaches.
| Aspect | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
|---|---|---|
| Process Order | Extract → Transform (in staging) → Load | Extract → Load (to warehouse) → Transform (in warehouse) |
| Data Transformation | Occurs in a separate processing server before loading. | Occurs directly within the target data warehouse. |
| Data Size | Best for smaller, structured data sets. Transformations can be slow for large volumes. | Ideal for large volumes of data (Big Data). Leverages warehouse scalability. |
| Data Type | Primarily handles structured data. Unstructured data requires complex logic. | Easily handles structured, semi-structured, and unstructured data. |
| Speed (Time to Data) | Slower. Data is only available after the entire transformation step is complete. | Faster. Raw data is loaded and available for use almost immediately. |
| Warehouse Requirement | Works with traditional on-premises data warehouses and cloud platforms. | Requires a powerful cloud data warehouse (e.g., Snowflake, BigQuery, Redshift). |
| Maintenance | High. Requires maintaining a separate transformation engine and custom scripts. | Lower. Relies on SQL and the managed services of the cloud data warehouse. |
| Cost Model | Often involves fixed costs for hardware and software licenses. | Typically a pay-as-you-go model for storage and compute resources. |
Key Differences Between ETL and ELT Explained
Beyond the high-level comparison, several key differences have practical implications for your data teams and business operations. Let's explore these distinctions in more detail.
Process Order and Logic
The most obvious difference is the sequence of operations. ETL follows a rigid, step-by-step process. This makes it predictable but also inflexible. If you need to change a transformation, you must modify the middle of the pipeline.
In contrast, ELT decouples the loading and transformation steps. This separation allows for greater agility. Data teams can load data first and then experiment with different transformation models without reloading the data.
Data Availability and Raw Data Retention
With ELT, raw data is always preserved in the data warehouse. This creates a historical archive that can be reprocessed at any time. If a business question changes or a mistake is found in a transformation, you can simply rerun the transformation on the original raw data.
In ETL, the raw data is typically discarded after transformation to save space. This makes it difficult to go back and perform new types of analysis that weren't planned for initially.
Scalability and Flexibility for Growth
ELT is inherently more scalable. It leverages the massively parallel processing (MPP) architecture of modern cloud data warehouses. As your data volume grows, you can simply scale up your warehouse resources to handle the load.
ETL scalability is often limited by the capacity of the dedicated transformation server. Scaling an ETL system can require significant investment in new hardware or more powerful software licenses.
This makes building a scalable data-driven marketing strategy more achievable with ELT.
Compliance and Handling of Sensitive Data
ETL provides a distinct advantage for compliance. The transformation step allows you to remove, mask, or tokenize sensitive data before it ever lands in your data warehouse. This reduces the risk of data exposure and simplifies compliance with regulations like GDPR and HIPAA.
With ELT, raw, potentially sensitive data is loaded into the warehouse first. This requires robust security controls, data governance policies, and access management within the warehouse itself to ensure compliance.
Required Skillsets and Team Structure
The skillsets needed for each approach differ. ETL tools often have graphical user interfaces but can also require specialized developers proficient in languages like Python or Java for complex transformations.
ELT, on the other hand, is heavily reliant on SQL. This democratizes the transformation process, as SQL is a common skill among data analysts and engineers. Your team can focus on data modeling with tools like dbt rather than managing complex pipeline infrastructure.
When to Choose ETL: Traditional Strengths in a Modern World
Despite the popularity of ELT, the traditional ETL process remains the right choice in several key scenarios. Its strengths in data governance, structure, and security are invaluable for certain use cases.
For Businesses with Strict Compliance Needs
If your organization operates in a highly regulated industry such as healthcare (HIPAA) or finance (PCI DSS), ETL is often the safer choice.
The ability to pre-process data and remove sensitive information before it reaches the target system is a powerful compliance feature. It minimizes the "attack surface" for sensitive data and makes audits simpler.
When Working with Smaller, Structured Datasets
For smaller data volumes that are primarily structured (coming from relational databases), the overhead of a cloud data warehouse for ELT might be unnecessary. ETL tools are mature and efficient at handling these workloads.
The process is straightforward and provides clean, reliable data without the complexity of in-warehouse transformations.
For On-Premises Data Warehousing Infrastructure
If your company's data infrastructure is primarily on-premises, ETL is the natural fit.
Most on-premises data warehouses lack the massive parallel processing power of their cloud counterparts. Performing large-scale transformations within an on-premises warehouse would be slow and inefficient. ETL uses a dedicated staging server for this work, preserving the performance of the target warehouse for analytics queries.
When Data Transformation Logic is Stable
When your business rules and data transformation requirements are well-defined and do not change frequently, ETL provides a robust and reliable solution.
You can build and optimize the transformation logic once, creating a stable pipeline that consistently delivers high-quality data. This is common in established reporting processes where metrics are standardized across the organization.
When to Choose ELT: The Modern Approach for Cloud Analytics
ELT has become the default choice for modern, cloud-native companies. Its flexibility, scalability, and speed are perfectly suited for the demands of today's data landscape.
For Leveraging Cloud Data Warehouses
If you are using or plan to use a cloud data warehouse like Snowflake, BigQuery, Amazon Redshift, or Databricks, ELT is the way to go.
These platforms are built for this workflow. They separate storage and compute, allowing you to ingest massive amounts of data cheaply and then apply processing power on-demand for transformations. ELT is designed to take full advantage of this architecture.
When Dealing with Large Volumes of Diverse Data
ELT is purpose-built for the age of big data. It can easily handle terabytes or even petabytes of data. More importantly, it excels with semi-structured (JSON, XML) and unstructured data (text, images) that are difficult for traditional ETL systems to parse.
This allows you to build a comprehensive data lakehouse architecture.
For Organizations Needing Real-Time Insights
Because ELT loads data immediately, it dramatically reduces the time from data generation to data availability. This enables near real-time analytics use cases. For example, an e-commerce company can analyze user clickstream data within minutes to personalize the customer experience. This speed is crucial for reporting automation that powers timely business decisions.
When Agility and Evolving Business Questions are the Norm
Modern businesses need to be agile. Business requirements change, and new analytical questions arise constantly. ELT supports this agility. By storing raw data, data teams can always go back and create new data models and reports without having to re-architect the entire data ingestion pipeline. This is a huge advantage for teams that practice data exploration and discovery.
The Rise of the Data Lake and its Impact on ELT
The conversation about ETL vs ELT is incomplete without mentioning the data lake. A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. The ELT process is a natural partner to the data lake concept.
How Data Lakes Complement the ELT Process
In a modern data stack, the ELT process often uses a data lake as the initial loading target. Raw data is extracted from sources and dumped into a low-cost storage layer like Amazon S3 or Google Cloud Storage. This acts as the "L" (Load) step.
From there, the data can be transformed and moved into a more structured data warehouse for analysis. This creates a flexible, two-tiered storage system.
Storing Raw Data for Future, Unforeseen Analysis
The primary benefit of a data lake is that you don't need to define a schema or purpose for your data before you store it. You can collect everything.
This is incredibly valuable because you may not know today what questions you'll need to answer tomorrow. Having a complete historical record of raw data ensures that future data science and machine learning projects will have the richest possible dataset to work with.
How Improvado Bridges the Gap Between ETL and ELT
Choosing between ETL and ELT doesn't have to be a rigid, all-or-nothing decision. Modern data platforms like Improvado offer the flexibility to implement the data integration strategy that best fits your needs.
A Flexible Platform for Any Data Integration Strategy
Improvado's platform is not strictly ETL or ELT, it's both.
It provides the flexibility to choose your approach. You can use Improvado to extract and load raw data directly into your cloud data warehouse, following an ELT pattern.
Alternatively, you can leverage Improvado's managed transformation layer to clean, map, and normalize your data before it's loaded, following an ETL pattern. This adaptability allows you to use the right process for the right data source.
"Improvado helped us gain full control over our marketing data globally. Previously, we couldn't get reports from different locations on time and in the same format, so it took days to standardize them. Today, we can finally build any report we want in minutes due to the vast number of data connectors and rich granularity provided by Improvado.
Now, we don't have to involve our technical team in the reporting part at all. Improvado saves about 90 hours per week and allows us to focus on data analysis rather than routine data aggregation, normalization, and formatting."

Automating Data Extraction for Hundreds of Sources
The most time-consuming part of any data pipeline is building and maintaining connectors to all your data sources.
Improvado solves this with a library of over 1,000+ pre-built connectors for marketing, sales, and analytics platforms, including offline and online sources, legacy systems and niche connectors.
This automates the "Extract" step, saving your engineering team thousands of hours. You can trust our data extraction tools and techniques to be reliable and up-to-date.
Managed Transformation for Clean, Analytics-Ready Data
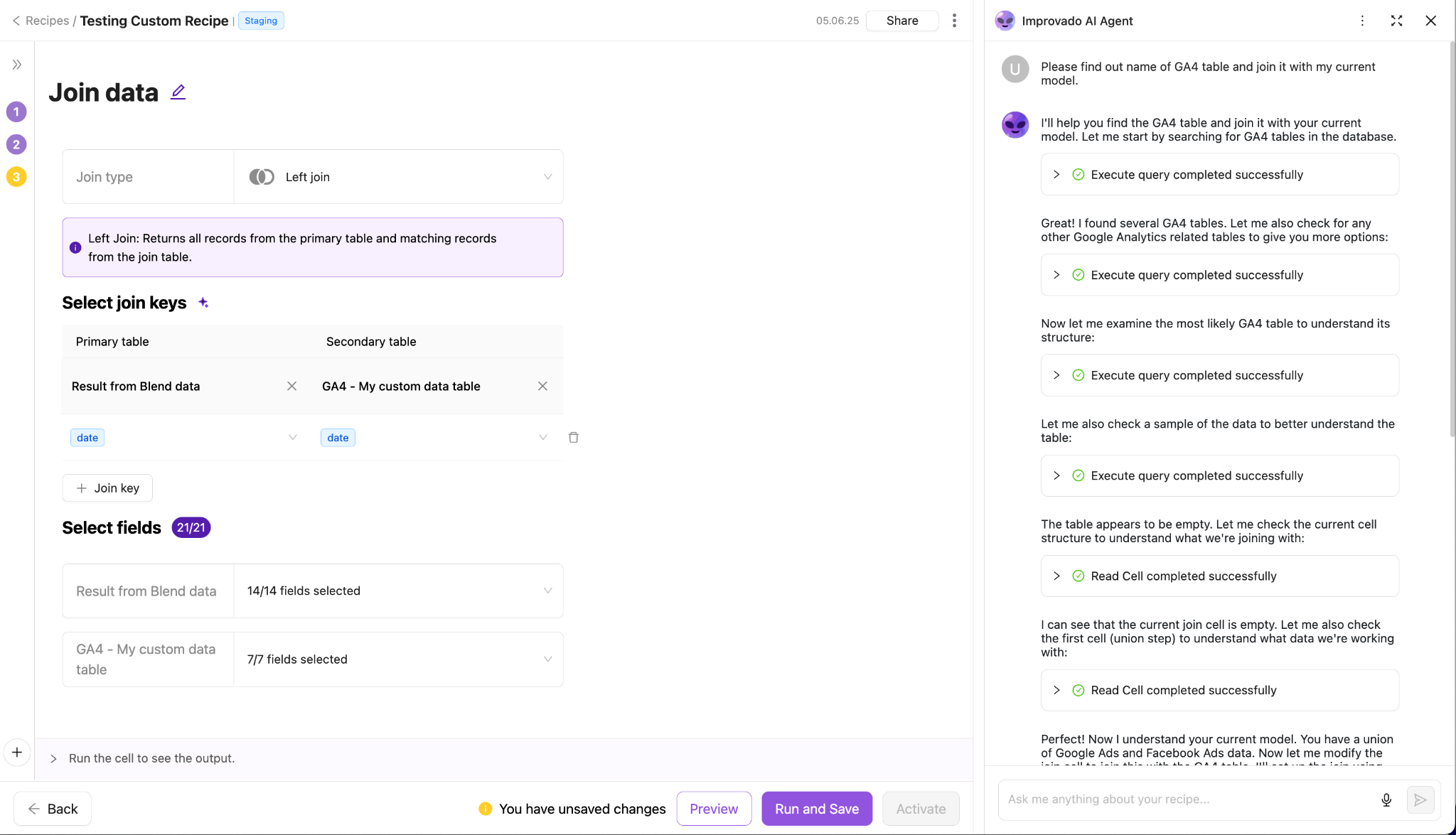
For marketing data, raw data is often messy and inconsistent. Different platforms use different metric names and attribution windows. Improvado's powerful data transformation capabilities can automatically harmonize this data into a standardized model.
With Improvado, you can:
- Use Automated Recipes to apply pre-built transformation logic for common marketing metrics and naming conventions
- Standardize channel taxonomies, attribution windows, and currency conversions with automated rule sets
- Leverage AI Agent to generate SQL-based transformations from natural-language instructions
- Create reusable, version-controlled transformation workflows without engineering support
- Automatically detect schema changes and adjust pipelines to prevent data breaks
- Apply calculated metrics and business logic consistently across all reporting destinations
This "managed ETL" approach provides the benefits of clean data without the manual effort, ensuring your team has a single source of truth for analysis.
Loading Data into Your Preferred Destination
Whether you use a data warehouse, a data lake, or a BI tool, Improvado can load your data where you need it. We have seamless integrations with destinations like Google BigQuery, Snowflake, Tableau, and Power BI.
This flexibility ensures that our platform fits perfectly into your existing data stack, enhancing your capabilities without forcing you to change your core infrastructure.


