.png)
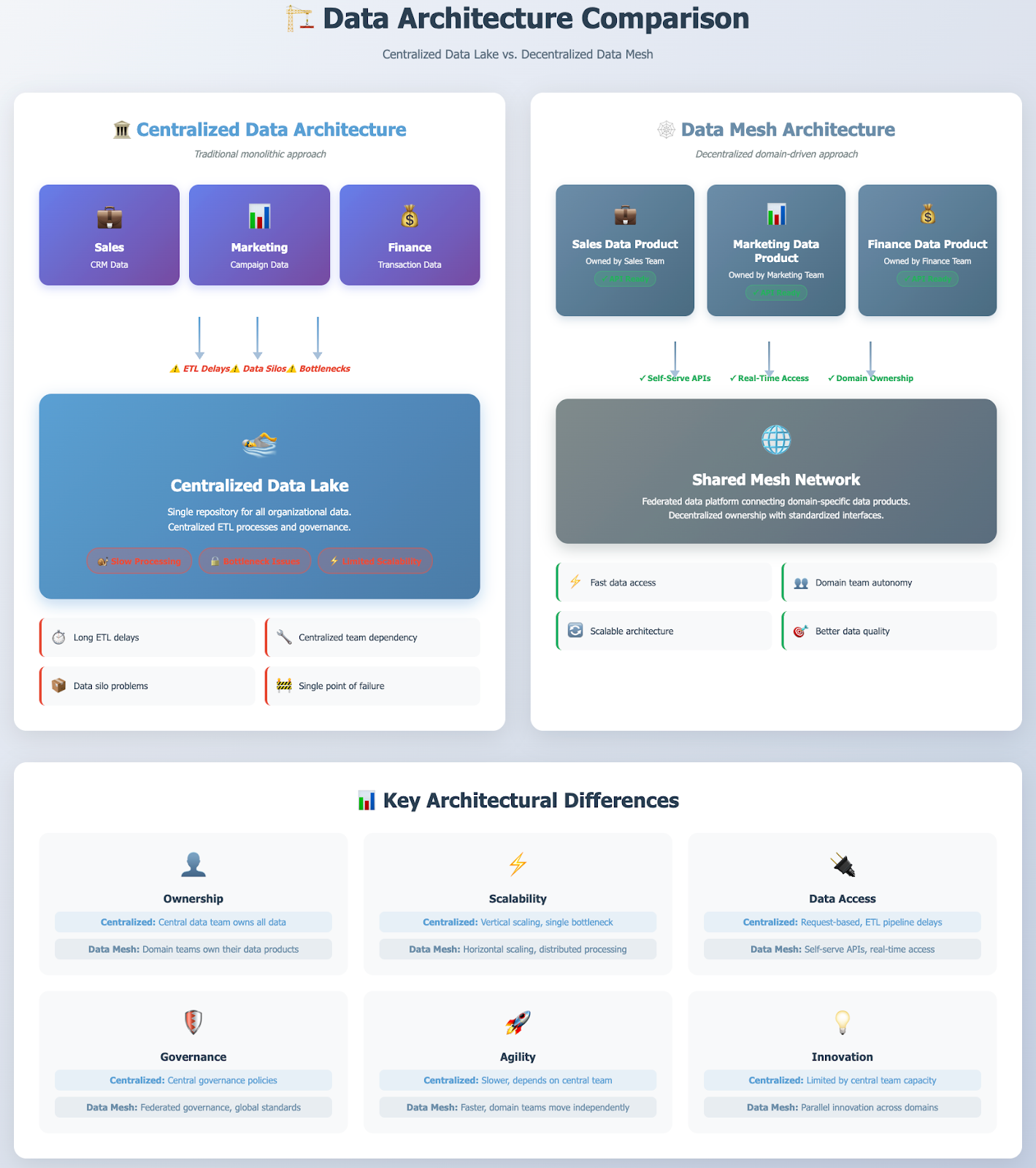
In the quest to become truly data-driven, enterprises have invested heavily in centralized data platforms like data warehouses and data lakes. Yet, many still struggle with data silos, slow delivery, and questionable data quality. The core issue is often a monolithic architecture that can't scale with organizational complexity. A new paradigm, the data mesh, offers a solution by decentralizing data ownership and treating data as a product.
First proposed by Zhamak Dehghani in 2019, the data mesh is a socio-technical approach to data architecture. It shifts the responsibility for analytical data away from a central data team and places it directly into the hands of the business domains that produce and understand the data best.
This article breaks down what a data mesh is, how it differs from traditional data architectures, and why it’s becoming the preferred model for large organizations seeking agility and scalability.
Key Takeaways
- Decentralized architecture: Data mesh is a decentralized data architecture that moves away from monolithic data lakes and warehouses, focusing on domain-oriented data ownership.
- Four core principles: The framework is built on four key principles: domain ownership, data as a product, a self-serve data platform, and federated computational governance.
- Solves scalability issues: It is designed to overcome the bottlenecks and scalability challenges inherent in traditional, centralized data platforms as organizations grow.
- Cultural and technical shift: Implementing a data mesh is not just a technology change; it requires a significant cultural shift in how an organization thinks about and manages its data.
Why Use a Data Mesh? Challenges It Solves
The move toward a data mesh is a direct response to the friction and limitations encountered with traditional centralized data platforms. As companies grow, these systems often fail to deliver on their promise of agility and insight.
A data mesh directly addresses several critical pain points:
- Organizational scaling bottlenecks: In a centralized model, a single data team is responsible for ingesting, transforming, and serving data for the entire organization. This team quickly becomes overwhelmed with requests from various business domains, creating a bottleneck that slows down access to critical insights.
- Data silos and lack of context: While data lakes were meant to break down silos, they often become data swamps. Data is dumped into the lake without the business context known only by the domain teams. This leads to ambiguity and a lack of trust in the data.
- Slow responsiveness and time-to-value: The journey from a business need to a usable data asset is often long and complex. The central team's lack of domain expertise leads to back-and-forth communication, increasing the time it takes to deliver data products and hampering business agility.
- Poor data quality and ambiguous ownership: When data is managed centrally, ownership becomes diluted. The central data team lacks the context to validate data quality effectively, while domain teams feel disconnected from the analytical data derived from their systems. This leads to a "tragedy of the commons" where no one is truly responsible for the data's reliability.
The 4 Core Principles of Data Mesh
The data mesh framework is founded on four interconnected principles that work together to create a scalable, decentralized data ecosystem.
1. Domain-Oriented Decentralized Data Ownership and Architecture
This is the foundational principle. Instead of data flowing to a central platform owned by a single team, analytical data ownership is shifted to the business domains that are closest to the data.
For example, the marketing team owns its campaign data, the sales team owns its CRM data, and the finance team owns its transactional data. These cross-functional domain teams are responsible for the full lifecycle of their data, from source to consumption, ensuring higher quality and relevance.
2. Data as a Product
In a data mesh, data is not just a technical asset; it's a product created by domain teams for other data consumers (whether human or machine) to use.
This "data as a product" mindset means each dataset must be treated with the same rigor as a software product and must possess specific qualities:
- Discoverable: Data products must be easy to find, typically through a centralized data catalog.
- Addressable: Each product should have a unique, permanent, and easily accessible location.
- Trustworthy: Data quality, lineage, and service-level objectives (SLOs) must be clearly defined and monitored.
- Self-Describing: Metadata, schema, and documentation are packaged with the data, making it understandable without needing to consult the producers.
- Interoperable: Data products adhere to global standards, allowing them to be easily combined with other products.
- Secure: Access controls and governance policies are applied directly to the data product itself.
3. Self-Serve Data Infrastructure as a Platform
To empower domain teams to build and manage their own data products, they need a central, self-serve data platform. This platform is managed by a central data platform team, whose role shifts from being a data provider to an enabler. They build and maintain a domain-agnostic platform that provides the tools and services needed for the entire data product lifecycle.
This includes solutions for:
- Data ingestion and storage
- Data pipelines and transformation
- Data cataloging and data discovery
- Access control and security
- Monitoring and observability
This central platform provides the tools for data integration, transformation, and governance.
For marketing and sales domains, for example, a platform like Improvado can automate the creation of data products by integrating data from over 500 sources, handling complex transformations, and ensuring data is analysis-ready without heavy engineering lift from the domain team.
4. Federated Computational Governance
Decentralization requires a new model for governance. A data mesh implements federated computational governance, which establishes a balance between domain autonomy and the need for global interoperability.
A governance guild, composed of representatives from domain teams and the central platform team, defines global policies and standards (e.g., for security, privacy, and data quality). These rules are then automated and embedded into the self-serve platform, ensuring compliance without creating a manual, bureaucratic process.
Data Mesh Architecture Explained
A common misconception is that a data mesh is a specific technology or product you can buy.
In reality, it is a logical architecture that describes how different components interact. It is not about replacing your existing data infrastructure but rather organizing it differently.
In a data mesh architecture, data largely remains within its operational domain. Domain teams are responsible for exposing their analytical data as data products through standardized output ports, such as APIs. These data products can be queried directly or consumed by other domains to create new, aggregated data products.
A central data catalog serves as a discovery layer, allowing data consumers across the organization to browse and understand the available data products. Existing data warehouses or data lakes do not disappear; instead, they can become nodes within the mesh.
For instance, an enterprise data warehouse could be refactored to serve high-quality, aggregated data products to the rest of the organization, effectively acting as a specialized domain.
What Are the Business Benefits of a Data Mesh?
Adopting a data mesh architecture can deliver significant business value, especially for large and complex organizations.
- Data democratization: By making high-quality data products easily discoverable and accessible, a data mesh empowers business users and analysts to answer their own questions without relying on a central data team.
- Greater agility and scalability: The decentralized model allows teams to work in parallel. As the organization grows, new domains can be added to the mesh without re-architecting the entire system, allowing the data platform to scale with the business.
- Improved data quality and trust: When domain teams own their data products, they are directly accountable for their quality, accuracy, and reliability. This proximity to the data source leads to higher-quality analytical data and increased trust among consumers.
- Faster time to value: Self-serve tools and clear data ownership accelerate the process of creating and consuming data insights. This reduces the time-to-market for data-driven projects and initiatives.
- Cost efficiency: By reducing the reliance on a single, massive monolithic platform and eliminating data duplication, organizations can optimize their infrastructure costs.
What Are the Challenges in Implementing a Data Mesh?
While the benefits are compelling, implementing a data mesh is a significant undertaking with several challenges.
- Cultural and organizational shift: This is often the biggest hurdle. A data mesh requires a fundamental shift in mindset from centralized data control to decentralized ownership and accountability. Gaining buy-in across the organization and restructuring teams is a complex change management process.
- Complexity in setup: Building a robust self-serve data platform requires significant upfront investment in platform engineering. Defining the initial federated governance model also takes considerable effort.
- Defining domain boundaries: Identifying the right boundaries for business domains (the "bounded context") can be difficult, especially in organizations with complex, overlapping functions.
- New skillset requirements: Domain teams need to develop new skills in data engineering, data product management, and data governance. This may require extensive training or hiring new talent.
As adoption ramps up, establish a feedback loop with the platform provider. Schedule regular check-ins with their customer success team to surface blockers, share user feedback, and adjust configurations as needed.
Improvado provides a dedicated customer success manager to all its enterprise clients. A structured feedback cadence ensures the platform evolves with the client's needs and drives long-term success across teams.
"We have weekly meetings with Improvado representatives, and that really helps get things done quicker. We can raise a ticket, ask them to look at it, and they’ll push it forward if needed.”

Data Mesh Use Cases and Examples
A data mesh architecture is versatile and supports a wide range of analytical use cases across different industries.
Business Intelligence (BI) and Analytics
A data mesh allows business units to independently build dashboards and reports by combining trusted data products from various domains. A marketing team, for instance, can combine its own campaign performance data product with a sales CRM data product to analyze marketing-influenced revenue without waiting for a central team.
Machine Learning and AI Projects
Data scientists can quickly discover and consume high-quality, analysis-ready data products from across the organization to train and deploy ML models. This accelerates the development lifecycle for projects like fraud detection, customer churn prediction, and product recommendation engines.
Customer 360 and Experience Optimization
Building a complete view of the customer requires data from multiple touchpoints. With a data mesh, a cross-functional team can create a "Customer 360" data product by consuming and joining data products from Sales (CRM data), Marketing (engagement data), Support (ticket data), and Product (usage data).
Industry-Specific Applications
- Finance: Global financial institutions use a data mesh to unify trading, risk, and compliance data from different regional domains, enabling holistic risk management while respecting data residency regulations.
- Retail: A retailer can create data products for inventory, sales, and customer behavior. These can be combined in real-time to optimize supply chains, personalize promotions, and improve the in-store experience.
- Healthcare: A healthcare provider can create separate data products for clinical records, patient administration, and research, sharing them securely across domains to improve patient outcomes and accelerate research.
Data Mesh vs. Data Lake vs. Data Fabric
It's important to distinguish data mesh from other common data architectures.
Data Mesh vs. Data Warehouse
A data warehouse is a centralized repository of structured, cleansed data optimized for BI and reporting (schema-on-write). A data mesh is a decentralized architecture where data ownership and products are distributed across domains. A warehouse can be a node within a mesh, serving highly curated, enterprise-wide data products.
Data Mesh vs. Data Lake
A data lake is a centralized repository that stores vast amounts of raw data in its native format (schema-on-read). While flexible, it can become a data swamp without proper governance. A data mesh contrasts by distributing ownership and focusing on creating clean, usable data products, not just storing raw data.
Data Mesh vs. Data Fabric
This is a subtle but important distinction.
A data mesh is a socio-technical architecture focused on organizational structure, domain ownership, and product thinking. A data fabric is a technology-centric solution that uses metadata, machine learning, and automation to connect disparate data sources and automate data integration and governance.
The two concepts are complementary: a data fabric can be the technological foundation that helps power a data mesh architecture.
| Feature / Dimension | Data Mesh | Data Lake | Data Fabric | Data Warehouse |
|---|---|---|---|---|
| Core Concept | Decentralized architecture where domains own and serve data as products | Centralized repository for storing raw, unstructured or semi-structured data | Metadata-driven, technology-centric layer that connects and automates data integration | Centralized repository for structured, cleansed data optimized for analytics |
| Ownership Model | Distributed, data owned by individual business domains | Centralized, owned by IT or data engineering | Centralized orchestration, enables distributed access via automation | Centralized, managed by data engineering and BI teams |
| Governance Approach | Federated governance with shared standards and domain autonomy | Often weak – prone to “data swamp” without strong policies | Automated governance via metadata, ML, and lineage tracking | Centralized governance and strict schema enforcement |
| Data Type and Structure | Any (structured, semi-structured, unstructured) – organized as reusable data products | Any type of raw data | Any – connected across systems through metadata | Primarily structured data |
| Integration and Scalability | Scales through domain-level ownership and APIs | Scales storage easily but struggles with metadata and quality at scale | Scales via automation and intelligent integration | Scales with data volume but requires heavy ETL or ELT management |
| Primary Users | Cross-functional teams (data owners, analysts, product managers) | Data engineers and data scientists | Data architects and governance teams | Analysts and business intelligence users |
| Purpose / Outcome | Democratize trusted, usable data across domains | Store and explore large volumes of raw data | Automate and unify enterprise data integration and management | Enable consistent enterprise reporting and analytics |
| Technology Focus | Organizational and operational model | Storage and ingestion | Integration and automation | Analytics and reporting |
| Ideal Use Case | Large enterprises seeking scalable, domain-based data ownership | Central data repository for analytics and ML exploration | Complex multi-cloud or hybrid environments requiring seamless data connectivity | Standardized enterprise reporting and historical analysis |
How Do You Implement a Data Mesh?
Implementing a data mesh is an evolutionary journey, not a big-bang project. It should be approached iteratively.
Step 1: Assess Your Organizational Readiness
Before writing any code, evaluate if your organization has the culture and executive sponsorship for such a significant shift. A data mesh is most successful in organizations that are already moving toward a decentralized, domain-driven structure.
Step 2: Define Domain Boundaries and Identify Data Products
Work with business leaders to map out business domains and their corresponding data. Identify high-value analytical data that can be modeled as the first set of data products.
Step 3: Develop a Self-Service Data Platform
Begin building the initial version of the self-serve platform. Focus on providing the core tools that a pilot team will need to build, deploy, and manage their first data product.
Step 4: Establish Federated Governance
Form a governance guild with representatives from key domains. Start by defining a lightweight set of global standards for data product interoperability, security, and quality.
Step 5: Start with a Pilot Project and Iterate
Select one or two enthusiastic and capable domain teams for a pilot project. Help them build and launch the organization's first true data products. Use the learnings from this pilot to refine the platform, governance model, and rollout strategy for other domains.
How Improvado Supports a Data Mesh Strategy
Implementing a full data mesh is a major strategic initiative. However, organizations can start applying its principles to specific high-complexity domains like marketing and sales.
While a full data mesh implementation is a significant undertaking, Improvado's enterprise marketing intelligence platform provides a practical starting point. It acts as a specialized 'mesh node' for your marketing and sales domains, automating data pipelines and creating a unified, reliable source of truth that can be easily shared as a data product with the rest of the organization.
By handling the complexity of integrating hundreds of marketing and sales data sources, Improvado allows your marketing domain to deliver high-quality, analysis-ready data products without needing deep data engineering expertise, accelerating your journey toward a scalable data culture.


