
The MarTech and AdTech landscape continues to expand. Each platform generates its own datasets, schemas, and attribution logic. As channel volume grows, data fragmentation increases. Marketing teams are left reconciling inconsistent metrics, duplicated records, and misaligned campaign structures.
Most platforms export data, but they do not standardize it. Timezones differ. Naming conventions vary. Attribution windows conflict. Without structured cleansing, reporting becomes unreliable and cross-channel analysis breaks down.
Marketing data cleansing is not optional. It is the prerequisite for accurate performance measurement and budget optimization. In this guide, you’ll learn what marketing data cleansing involves and how to implement it efficiently within a scalable analytics workflow.
Key Takeaways:
- Data cleansing is foundational: It's the process of detecting and correcting errors in your marketing datasets to ensure high data quality for reliable decision-making.
- Dirty data is expensive: Inaccurate data leads to flawed campaign analysis, poor personalization, wasted marketing budgets, and damage to brand reputation.
- Common errors are identifiable: Key issues include duplicates, misspellings, formatting errors, missing values, and outdated contact information like old phone numbers or emails.
- A systematic process is key: A successful data cleaning process involves auditing data, setting quality standards, standardizing, deduplicating, and validating information.
- Automation is non-negotiable: Manual data cleansing is not scalable. ETL platforms like Improvado automate the entire process, saving hundreds of hours and ensuring consistent data quality.
What Is Marketing Data Cleansing? And Why It's Not Just 'Data Cleaning'?
Let's start with a clear definition. Marketing data cleansing is the comprehensive process of identifying, correcting, and removing corrupt, inaccurate, or irrelevant records from a dataset. It's also known as data cleaning or data scrubbing.
The goal is to produce a clean, consistent, and reliable dataset that fuels accurate analytics and effective marketing efforts.
While the terms are often used interchangeably, it's helpful to understand the nuances:
- Data cleansing: The overall process of fixing errors. This is the main focus of our guide.
- Data hygiene: Refers to the ongoing practices and policies that keep data clean over time. Cleansing is the cure; hygiene is the prevention.
- Data enrichment: The process of appending third-party data to your existing records to make them more complete. For example, adding company size or industry to a customer record.
- Data normalization: A specific step within cleansing. It involves organizing data to appear similar across all records. For instance, ensuring all state names are two-letter abbreviations (e.g., "CA" instead of "California" or "Calif.").
The High Cost of 'Dirty Data': How Inaccurate Data Sabotages Marketing ROI
Ignoring data quality is an active drain on resources. "Dirty data" actively works against your goals. It creates significant problems across the entire marketing and sales funnel, leading to poor decision-making and financial loss.
Flawed Strategic Decision-Making
Company leadership relies on marketing reports to make critical business decisions. If your data is inaccurate, your reports will be misleading. You might invest more in a channel that appears successful but is actually underperforming due to duplicated conversion data.
This leads to misallocated budgets and missed growth opportunities. Poor data quality costs organizations an average of $12.9 million per year.
Wasted Marketing and Sales Efforts
Imagine your sales team spending hours calling invalid phone numbers. Or your email campaign having a high bounce rate due to outdated addresses. This is a direct result of dirty customer data.
Poor data wastes your team's time, hurts morale, and directly impacts the bottom line. Clean data ensures your marketing efforts reach their intended audience effectively.
Before Booyah Advertising implemented Improvado, their analytics team struggled with frequent accuracy issues. Entire days of data were missing, duplicates distorted performance metrics, and aggregation across over 100 clients required extensive manual reconciliation.
After the migration, Booyah realized 99.9% data accuracy and cut daily budget-pacing updates from hours to 10-30 minutes. Improvado’s unified pipelines, normalization logic, and real-time refresh capability gave the agency full visibility and control over multi-source data (15–20 feeds per client).
“We never have issues with data timing out or not populating in GBQ. We only go into the platform now to handle a backend refresh if naming conventions change or something. That's it.
With Improvado, we now trust the data. If anything is wrong, it’s how someone on the team is viewing it, not the data itself. It’s 99.9% accurate.”

Poor Personalization and Customer Experience
Personalization is no longer a luxury. It's an expectation.
Customers expect relevant offers and communications. Dirty data makes this impossible. Sending an email with the wrong name, recommending products a customer just bought, or targeting them with irrelevant ads creates a poor experience.
This can damage brand perception and drive customers to competitors.
Inaccurate Measurement and Attribution
How can you prove marketing's value without reliable data?
Dirty data makes it impossible to accurately measure campaign performance. Inconsistent UTM parameters or duplicate lead entries can completely skew your analysis. You won't know which channels truly drive revenue.
This makes optimizing your marketing attribution models a guessing game rather than a data-driven science.
Common Types of Dirty Marketing Data You Need to Find and Fix
Data can become "dirty" in many ways. Understanding these common error types is the first step toward fixing them.
These issues often arise from manual data entry, system migration errors, or integrating multiple, disparate data sources.
1. Duplicate Records
This is one of the most common problems. The same lead or customer exists multiple times in your database.
For example, "John Smith," "J. Smith," and "john.smith@email.com" might all be the same person. Duplicates inflate your customer counts, skew analytics, and can lead to sending the same person multiple marketing messages, which is annoying for the recipient.
The process of removing them is called deduplication.
2. Inaccurate or Incomplete Data
This category includes a wide range of issues:
- Missing values: Fields that are left blank, like a contact without an email address or a lead without a company name.
- Misspellings: Simple typos in names, cities, or email domains (e.g., "Gnial.com" instead of "Gmail.com").
- Outdated information: Data that was once correct but is no longer valid. This includes old phone numbers, job titles, or physical addresses.
- Misfielded values: Information entered in the wrong field, like a city name in the state field.
3. Inconsistent Formatting
Data from different sources often has different formatting. This lack of standardization makes analysis and segmentation difficult.
Examples include:
- Names: "John Smith" vs. "Smith, John".
- Phone numbers: (555) 123-4567 vs. 555-123-4567 vs. 5551234567.
- Dates: 10/25/2025 vs. 25-10-2025 vs. Oct 25, 2025.
- Metric naming: One platform calls it "Impressions," another "Views," and a third "Imps." This creates chaos in reporting.
4. Compliance and Governance Issues
Data quality is also a legal issue. Regulations like GDPR and HIPAA have strict rules about handling customer data. Holding inaccurate or outdated personal information can lead to significant fines.
Data cleansing ensures you honor opt-out requests promptly and maintain only necessary, accurate data, keeping you compliant.
A Step-by-Step Guide to the Marketing Data Cleansing Process
A structured approach ensures that your data cleansing efforts are thorough and effective. This data cleaning process can be broken down into several key steps.
While manual execution is possible for very small datasets, automation is essential for scalability.
Step 1: Audit and Profile Your Data
You can't fix what you don't understand. The first step is to analyze your dataset to identify the types and extent of errors.
Data profiling tools can scan your database to find inconsistencies, outliers, and patterns of errors. This gives you a baseline for your data quality and helps you prioritize your cleansing efforts.
Step 2: Define Your Data Quality Standards
Establish clear rules for what "clean data" means for your organization. This involves creating a data dictionary that defines each field, its required format, and acceptable values.
For example, you might decide all country fields must use the two-letter ISO code. These standards become the blueprint for your cleansing operations.
Step 3: Standardize and Normalize Data
Using the standards from Step 2, you can begin the correction process. This involves parsing data into correct fields and applying consistent formatting.
For example, you might transform all phone numbers to the `(XXX) XXX-XXXX` format. This step ensures that data from different sources can be accurately compared and aggregated within your complete marketing data pipeline.
Step 4: Match and Deduplicate Records
Identify and merge duplicate records. This is a complex step that often requires sophisticated matching algorithms (fuzzy matching) to find non-identical duplicates (e.g., "Rob Smith" vs. "Robert Smith").
The goal is to create a single, authoritative record for each customer or lead, often called a "golden record."
Step 5: Validate and Verify Information
Check your data against trusted sources to confirm its accuracy. This can involve using services to validate email addresses and phone numbers.
For B2B data, you might verify that a contact still works at a specific company. This ensures your data isn't just clean but also up-to-date and correct.
Step 6: Append and Enrich Data
Once your data is clean, you can make it more valuable. Data enrichment involves adding new information from third-party sources. You could append demographic data to B2C records or firmographic data (like industry and revenue) to B2B records.
This enables more precise targeting and segmentation.
Step 7: Automate and Monitor
Data cleansing is not a one-time project. Marketing data is constantly flowing. New campaigns start. Platform schemas change. Naming conventions drift. Manual cleansing and one-off scripts do not scale.
The only sustainable solution is automation.
Automated data integration systems handle extraction, standardization, and validation on a regular schedule. These systems reduce human effort and surface issues early.
Improvado automates these tasks across hundreds of marketing, sales, and revenue sources. It connects to each source via maintained API connectors and ingests raw data into your warehouse on a schedule you define.
Improvado applies structured transformation logic to ensure consistency across channels:
- Schema standardization: Source fields are mapped to a common schema. Campaign, ad group, and keyword attributes use a unified structure regardless of origin.
- Metric alignment: Improvado enforces consistent definitions for core metrics such as impressions, clicks, conversions, revenue, and cost. This prevents mismatches caused by platform-specific naming conventions.
- Currency and timezone normalization: All financials are aligned to a single currency and timezone, reducing seasonal and regional discrepancies.
- Identifier resolution: Customer, campaign, and product identifiers are mapped across systems to support unified analysis.
- Business logic transformations: You can apply reusable transformation rules (e.g., merge duplicate campaign names, enforce naming conventions, derive custom metrics) directly inside your warehouse.
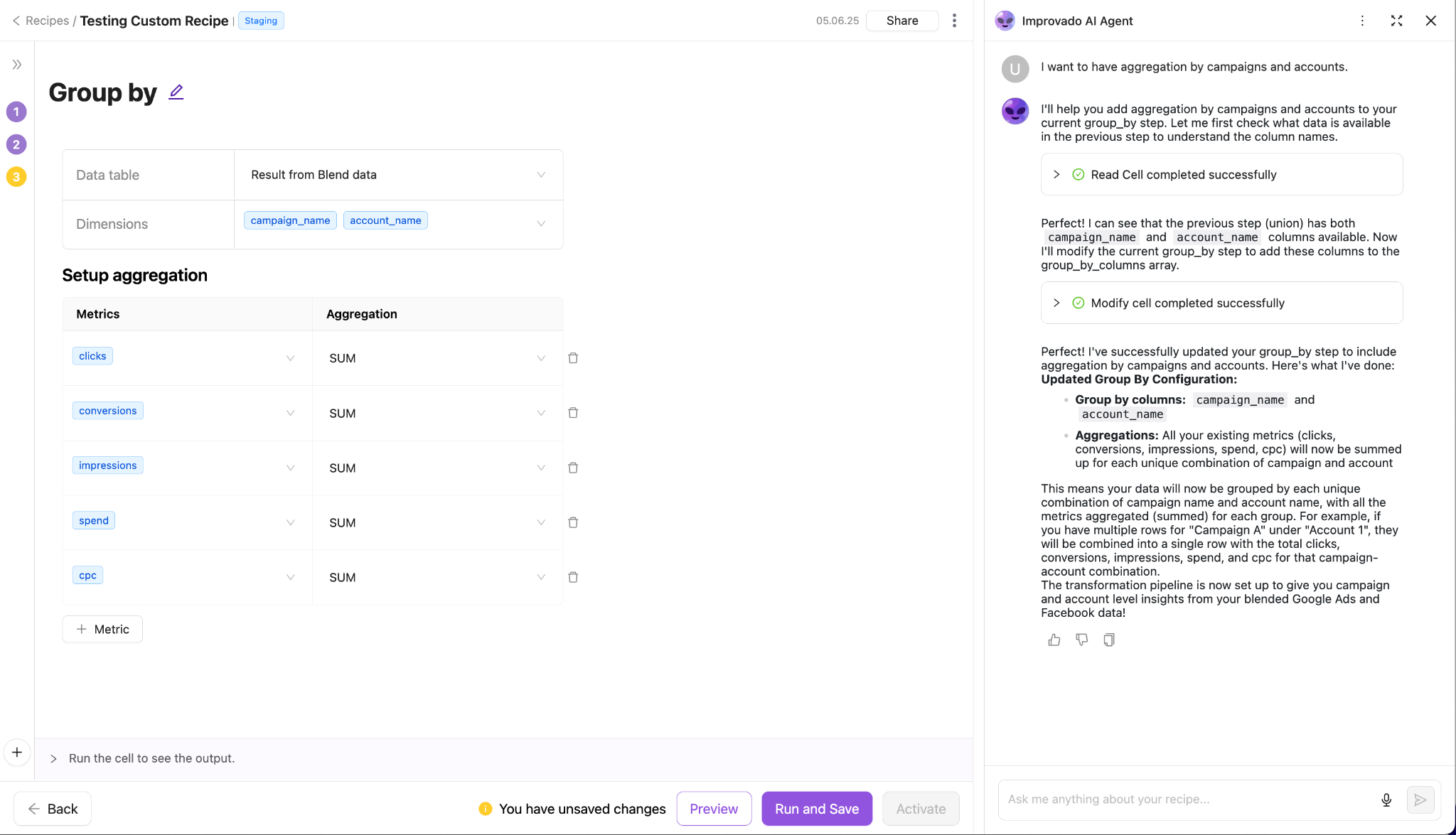
These steps convert raw, siloed data into analysis-ready datasets that BI tools and models can rely on.
Marketing Data Cleansing Best Practices for Sustainable Data Quality
Following best practices ensures your data stays clean long-term. This transitions you from reactive data cleaning to proactive data hygiene.
- Establish data governance: Create clear ownership and responsibility for data quality within your organization. Appoint data stewards who are accountable for specific datasets.
- Invest in the right tools: Manual cleansing in spreadsheets is unsustainable. Invest in dedicated data integration tools or ETL platforms that automate cleansing workflows.
- Cleanse data at the source: Whenever possible, prevent dirty data from entering your system in the first place. Use form validation and standardized picklists on your website to ensure clean data entry.
- Document everything: Maintain a central repository of your data standards, definitions, and cleansing rules. This ensures everyone in the company is on the same page.
- Schedule regular audits: Don't assume your automated processes are perfect. Periodically audit your data to catch new types of errors and refine your cleansing rules.
- Train your team: Educate everyone who handles data, from marketers to the sales team, on the importance of data quality and best practices for data entry.
Comparison: Manual vs. Automated Data Cleansing
Choosing the right approach to data cleansing is critical. While manual methods might seem sufficient for small tasks, they quickly become a bottleneck as data volume and complexity grow.
| Aspect | Manual Cleansing (e.g., Spreadsheets) | Automated Cleansing (e.g., Improvado) |
|---|---|---|
| Speed and Efficiency | Extremely slow and time-consuming. Not feasible for large datasets. | Lightning-fast. Processes millions of records in minutes. |
| Accuracy | Prone to human error. Typos and mistakes can introduce new problems. | Highly accurate. Rules-based logic ensures consistent application of standards. |
| Scalability | Does not scale. Becomes impossible as data sources and volume increase. | Highly scalable. Handles growing data volumes and complexity with ease. |
| Cost | Low initial tool cost, but very high labor cost in terms of employee hours. | Higher initial tool cost, but significantly lower long-term labor cost and higher ROI. |
| Maintenance | Requires constant, repetitive manual effort for new data. | Set-and-forget rules that run automatically. Requires only occasional refinement. |
| Real-Time Capability | Impossible. Data is already outdated by the time it is cleaned. | Enables real-time data cleansing as data is ingested, ensuring fresh insights. |
| Best For | One-time, very small, simple data cleanup tasks. | Any organization serious about data-driven marketing and scalable growth. |
How Data Cleansing Streamlines Key Marketing Functions
Clean, high-quality data is a strategic marketing asset. When your data is reliable, every aspect of your marketing becomes more effective.
Precision Personalization and Segmentation
Accurate data is the fuel for effective personalization. With clean demographic, firmographic, and behavioral data, you can create highly specific audience segments.
This allows you to deliver tailored messaging, content, and offers that resonate deeply with each group, dramatically improving engagement and conversion rates.
Trustworthy Reporting and Analytics
Clean data ensures that your analytics tell the true story of your performance. When metrics are standardized and duplicates are removed, your reports become a reliable source of truth.
This allows you to confidently present results to leadership and make sound strategic decisions. The accuracy of your KPI dashboards depends entirely on the quality of the underlying data.
Accurate Marketing Attribution
Attribution is the holy grail of marketing analytics, but it's impossible with messy data. Inconsistent campaign naming conventions or broken UTM tracking can make it impossible to connect marketing activities to revenue. Data cleansing standardizes this information, enabling you to build accurate models that show which channels and campaigns are truly driving results.
Enhanced Lead Scoring and Sales Alignment
A clean dataset strengthens the partnership between marketing and the sales team. With accurate lead information, you can implement a more effective lead scoring model.
This ensures that sales receives high-quality, well-vetted leads, increasing their efficiency and conversion rates. It eliminates the frustration of chasing down leads with bad contact information.
Improved Social Media and Content Strategy
By cleansing data from social platforms, you gain a clearer understanding of your audience. Accurate demographic and engagement data helps you refine your content strategy.
It ensures your social media analytics are based on real user interactions, not inflated by bots or duplicate profiles, leading to content that genuinely connects with your target audience.
Establishing a Long-Term Data Governance & Hygiene Strategy
Effective data management goes beyond a one-off cleanup project. To maintain high data quality, you need to build a sustainable data governance and hygiene strategy. This creates a culture where clean data is everyone's responsibility.
What is Data Governance?
Data governance is a system of rules, policies, standards, and processes for managing an organization's data. It defines who can take what action, upon what data, in what situations, using what methods.
For marketers, this means establishing clear guidelines for things like campaign naming conventions, UTM parameter usage, and data entry protocols in the CRM.
Key Pillars of a Data Hygiene Strategy
- Data stewardship: Assign individuals or teams as "stewards" responsible for the quality of specific datasets (e.g., a CRM manager is the steward of customer contact data).
- Clear policies: Document your data standards and make them easily accessible. This includes your data dictionary, formatting rules, and privacy policies.
- Ongoing training: Regularly train employees on data governance policies and the importance of data quality. Reinforce best practices for creating and handling data.
- Automated monitoring: Use tools to continuously monitor your data quality. Set up alerts that notify you of anomalies or sudden drops in data quality, allowing you to address issues proactively.
- Feedback loops: Create a simple process for data users (like the sales team) to report data errors they find. This helps you identify and fix issues quickly.
By implementing a strong data governance framework, you shift from constantly cleaning up messes to preventing them from happening in the first place. This is the hallmark of a truly data-driven organization.
Conclusion
Marketing data cleansing is not a technical afterthought. It is a prerequisite for accurate reporting, reliable attribution, and defensible budget decisions. As marketing stacks expand, inconsistencies in schemas, naming conventions, currencies, and attribution logic compound. Without structured cleansing, dashboards mislead, models break, and performance insights lose credibility.
Improvado embeds cleansing into the data pipeline. It automates ingestion, standardizes schemas, aligns metric definitions, normalizes currencies and timezones, and applies governed transformations inside your warehouse. This ensures that the data powering your analytics is consistent, validated, and analysis-ready.
If you want to replace manual data fixes with a controlled, automated foundation, request a demo and see how Improvado operationalizes marketing data cleansing at scale.


