%2520(1).png)
In the data-driven environment we all operate, organizations face a significant challenge. Data is everywhere. It lives in the cloud, on-premises, in marketing platforms, and in sales tools. This distribution creates data silos, making it nearly impossible to get a clear, unified view of business performance.
A new approach is needed to tame this complexity – a data fabric.
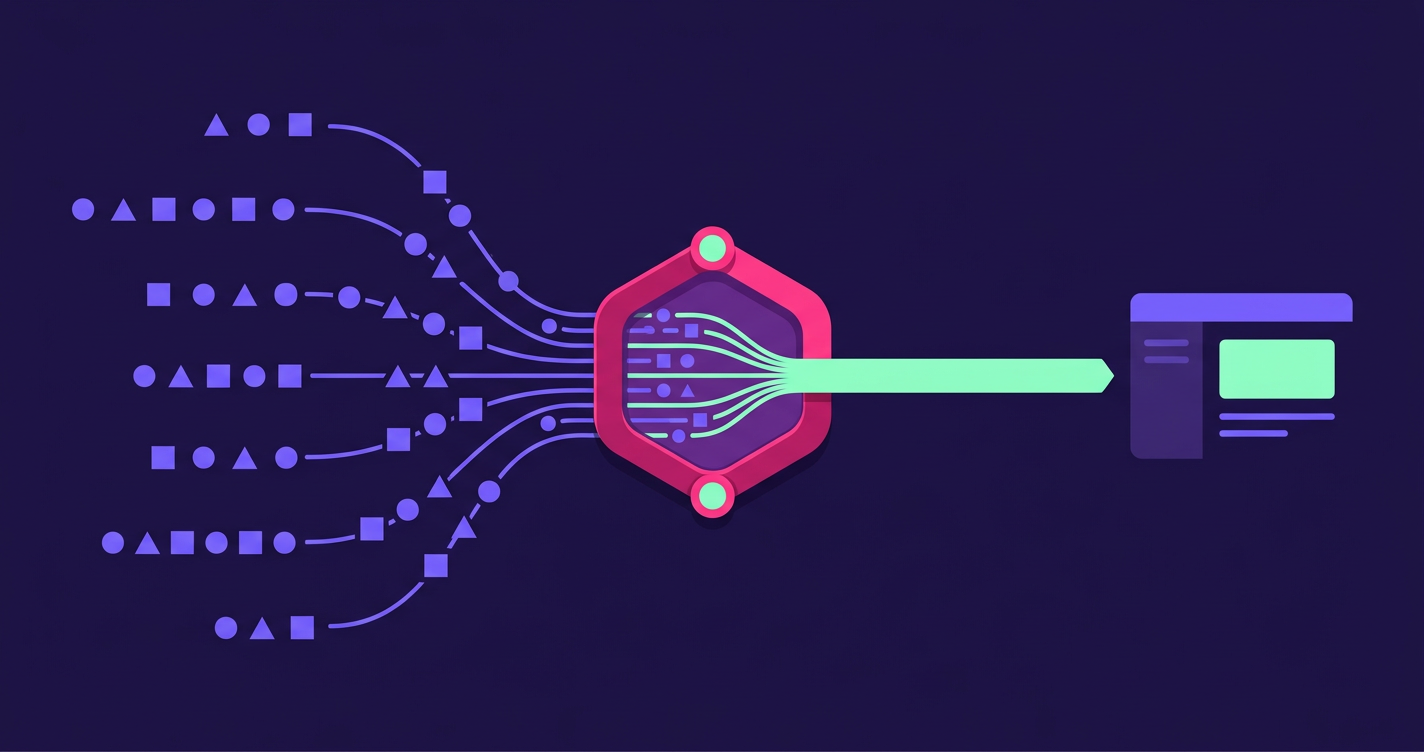
A data fabric is not just another tool or platform. It is a modern data architecture designed to connect all of your data, no matter where it resides. This guide explains exactly what a data fabric is, how it works, and why it's essential for any organization that wants to win with data.
Key Takeaways:
- Definition: A data fabric is an architectural approach that unifies data across disparate environments. It provides a single, consistent data management framework.
- Core function: It automates data discovery, governance, and consumption. This simplifies data access for all users, from data scientists to business analysts.
- Fabric vs. Mesh: A data fabric centralizes data management virtually, while a data mesh decentralizes ownership to business domains. They can complement each other.
- Key benefit: It drastically reduces the time to insight. It allows businesses to make faster, more accurate decisions by providing a real-time, holistic view of their data.
What Is a Data Fabric?
Imagine trying to weave a blanket with threads stored in different rooms of a large house. You would spend most of your time running back and forth, collecting threads, and trying to untangle them. This is the state of data management in many companies today.
A data fabric solves this problem. It acts like a master weaver who can access all the threads instantly, no matter their location.
At its core, a data fabric is a design concept. It is an architecture that creates a unified, intelligent layer over a company's entire data landscape. This layer connects all data sources, whether they are in a multi-cloud environment, a traditional data warehouse, or a modern data lake. It provides a single point of access to find, manage, and consume data.
Core Concept: A Unified Architectural Layer
The main idea of a data fabric is to abstract away the underlying complexity. Users do not need to know if data is stored in AWS, Google Cloud, or an on-premises server. They simply request the data they need, and the fabric delivers it.
This unified layer is not about moving all data into one giant repository. Instead, it accesses data where it lives. This approach is more efficient and less disruptive than traditional data consolidation projects. It enables a flexible and scalable data architecture.
Beyond Integration: Intelligent Data Management
A data fabric is more than just a set of pipes connecting data sources. It is an intelligent system. It uses AI and machine learning to understand and enrich the data flowing through it. It actively analyzes metadata, the data about your data. This active metadata helps automate tasks that were once manual.
For example, the fabric can automatically discover new data sources. It can profile data to understand its quality. It can even recommend relevant datasets to users based on their roles and past queries. This intelligence makes the entire data management process smarter and more efficient.
How a Data Fabric Connects Disparate Systems
A data fabric uses a variety of technologies to create its seamless network. Data virtualization allows it to query data from multiple sources as if it were a single database. API-based connectors provide access to hundreds of different applications and platforms. Data catalogs create an inventory of all available data assets, making them easy to find.
By weaving these technologies together, the fabric creates a cohesive whole from fragmented parts. This ensures that every data consumer in the organization has reliable, real-time access to the data they need to do their job effectively.
How Does a Data Fabric Work? Key Components & Mechanisms
A data fabric is a complex system with several interconnected components. Understanding these mechanisms is key to appreciating the power of this data architecture.
Data Ingestion and Connectivity
The foundation of any data fabric is its ability to connect to a vast array of data sources. This includes everything from structured databases and data warehouses to unstructured data in data lakes and streaming data from IoT devices.
The fabric uses pre-built connectors, APIs, and standard protocols to ingest data in batches or in real-time. This comprehensive connectivity ensures that no data source is left behind.
ASUS needed a centralized platform to consolidate global marketing data and deliver comprehensive dashboards and reports for stakeholders.
Improvado, an enterprise-grade marketing analytics platform, seamlessly integrated all of ASUS’s marketing data into a managed BigQuery instance. With a reliable data pipeline in place, ASUS achieved seamless data flow between deployed and in-house solutions, streamlining operational efficiency and the development of marketing strategies.
"Improvado helped us gain full control over our marketing data globally. Previously, we couldn't get reports from different locations on time and in the same format, so it took days to standardize them. Today, we can finally build any report we want in minutes due to the vast number of data connectors and rich granularity provided by Improvado.
Improvado saves us about 90 hours per week and allows us to focus on data analysis rather than routine data aggregation, normalization, and formatting."

Data Discovery and Metadata Management
Once connected, the data fabric must understand what data it has access to. It uses automated scanning and profiling techniques to build a comprehensive data catalog. This catalog is powered by active metadata, which captures technical, business, and operational information about each data asset.
This "knowledge graph" becomes the brain of the data fabric, mapping relationships between data points and providing context for users.
Data Governance and Security
A data fabric provides centralized data governance. It allows organizations to define and enforce data quality rules, access policies, and compliance regulations across all connected data sources.
This is a significant advantage over managing governance in a piecemeal fashion. Security policies are applied uniformly, ensuring sensitive data is protected regardless of where it is stored or who is accessing it. Learn more about establishing strong data governance to build a foundation of trust.
Data Transformation and Preparation
Raw data is rarely ready for analysis. The data fabric includes tools for data transformation and preparation. It supports both ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) patterns.
Users can clean, enrich, and reshape data to fit their analytical needs. Many of these transformations can be automated, reducing the burden on data engineers and allowing analysts to work with analysis-ready data.
Data Orchestration and Delivery
The data fabric orchestrates the entire data lifecycle. It manages the flow of data from source to consumer, ensuring reliability and performance. This involves building and managing a robust marketing data pipeline that can handle complex dependencies and workloads. Data is delivered to users through various methods, including direct queries, APIs, materialized views, or by publishing to business intelligence tools and applications.
Self-Service Data Access for Consumers
The ultimate goal of a data fabric is to empower users. It provides a self-service interface where business users, analysts, and data scientists can easily find and access the data they need.
This data marketplace experience democratizes data. It removes the bottleneck of IT requests and allows users to get insights faster. This self-service capability is a core tenet of both data fabric and data mesh philosophies.
The Core Pillars of Data Fabric Architecture
A successful data fabric architecture is built on several foundational pillars. They represent the technological and strategic principles that make the fabric concept a reality.
The Knowledge Graph: Mapping Your Data Landscape
At the heart of a modern data fabric architecture is a knowledge graph. This is not just a simple catalog of tables and files. It's a rich, interconnected map of all your data assets. The graph uses semantic technology to understand relationships between different data entities.
For example, it knows that a "customer ID" in your CRM system is the same as a "user_id" in your web analytics platform. This intelligent mapping is what enables the fabric to deliver a truly unified view of data.
AI-Powered Metadata Activation
Traditional data management relies on passive metadata. It's documentation that quickly becomes outdated. A data fabric uses AI-powered active metadata. This metadata is constantly collected, analyzed, and used to automate and optimize the data platform.
Machine learning algorithms can infer data lineage, detect data quality issues, and recommend data transformations. This AI layer turns the fabric from a passive data delivery system into an active, self-optimizing data management solution.
Unified Data Governance and Policy Enforcement
Data governance is not an afterthought in a data fabric; it's woven into its very core. The architecture allows for the central definition of data policies. These policies cover everything from data quality standards to access control rules based on user roles or data sensitivity.
The fabric then automatically enforces these policies across the entire distributed data landscape. This ensures consistent governance without requiring manual intervention for each individual data source.
Data Virtualization vs. Physical Data Movement
A key architectural choice in a data fabric is how to access data. Data virtualization allows the fabric to query data in place without moving it. This is ideal for real-time analytics and reduces data duplication.
However, for high-performance queries or complex transformations, it's often better to physically move and cache data in a high-performance analytics engine. A robust data fabric platform supports both approaches. It can intelligently choose the best method based on the specific query and use case.
A Multi-Cloud and Hybrid Environment Foundation
Modern enterprises operate in a hybrid, multi-cloud world. A data fabric architecture is designed specifically for this reality. It provides a consistent layer of abstraction across different cloud providers (like AWS, Azure, Google Cloud) and on-premises data centers.
This prevents vendor lock-in and allows organizations to choose the best environment for each workload. The fabric handles the complexities of cross-cloud data access and security, presenting a single logical data environment to the user.
Data Fabric vs. Data Mesh: A Strategic Comparison
In the world of modern data architecture, two terms often cause confusion: data fabric and data mesh. While both aim to solve the problems of distributed data, they approach the solution from different angles.
- A data fabric is primarily a technology-centric solution focused on unifying data access.
- A data mesh is an organizational and cultural paradigm shift focused on decentralizing data ownership.
The following table breaks down the key differences. It's important to note that they are not mutually exclusive. Many organizations find that a data fabric can be a powerful enabling technology for implementing a successful data mesh.
| Aspect | Data Fabric | Data Mesh |
|---|---|---|
| Core Philosophy | Centralized integration and augmented, unified data access. | Decentralized ownership and domain-oriented data as a product. |
| Architecture | A technology-centric, virtual layer that connects disparate data sources. | An organizational-centric, socio-technical approach to data architecture. |
| Data Ownership | Ownership is often managed centrally or in a federated model. | Data is owned and managed by specific business domains as "data products." |
| Implementation Focus | Focus on implementing tools, platforms, and a knowledge graph. | Focus on organizational change, principles, and self-serve infrastructure. |
| Primary Goal | Frictionless, governed access to all enterprise data. | Achieving business scalability, agility, and domain autonomy. |
| Key Technology | Active metadata graphs, AI/ML automation, data virtualization. | Data product APIs, self-serve data platform, computational governance. |
| Best For | Organizations seeking a unified view without major restructuring. | Large, complex organizations with highly distinct business domains. |
| Governance | Centrally defined and globally enforced governance policies. | Federated computational governance with a balance of global and local rules. |
Top 10 Benefits of Implementing a Data Fabric
Adopting a data fabric architecture is a strategic investment that yields significant returns. It transforms how an organization manages and utilizes its most valuable asset: data. The benefits extend beyond IT, impacting everything from operational efficiency to business innovation.
- Democratize data access at scale: A data fabric provides a self-service data marketplace. This empowers business users to find and use data without relying on technical teams, fostering a data-driven culture.
- Accelerate time to insight: By automating data integration and preparation, a data fabric dramatically reduces the time it takes to go from raw data to actionable insight. Decisions can be made in hours, not weeks.
- Enhance data quality and trust: Centralized governance and automated data quality checks ensure that users are working with reliable, accurate, and consistent data. This builds trust in analytics across the organization.
- Strengthen data governance and compliance: A data fabric makes it easier to comply with regulations like GDPR and CCPA. It provides a single point of control for enforcing security and privacy policies.
- Reduce data engineering overhead: The AI-powered automation within a data fabric handles many routine tasks like data discovery, lineage tracking, and transformation. This frees up skilled data engineers to focus on higher-value activities.
- Improve operational efficiency: With a unified view of data, businesses can streamline processes and identify inefficiencies. This is particularly true for complex operations like supply chain management or customer service.
- Enable advanced analytics and AI/ML: AI and machine learning models require access to large volumes of high-quality, integrated data. A data fabric provides the perfect foundation for training and deploying these advanced analytical models.
- Future-proof your data strategy: The flexible, modular architecture of a data fabric can easily adapt to new technologies, data sources, and cloud platforms. This ensures your data infrastructure remains modern and effective.
- Gain a 360-degree customer view: By integrating data from marketing, sales, and service systems, a data fabric creates a complete view of the customer journey. This enables personalized experiences and improved customer retention.
- Break down data silos permanently: The core purpose of a data fabric is to connect disparate data. It breaks down the organizational and technical barriers that create data silos, fostering better collaboration and holistic decision-making.
Key Use Cases for a Data Fabric in Marketing Analytics
Marketing departments are often overwhelmed by the sheer volume and variety of data from countless channels and platforms. A data fabric is the ideal solution to bring order to this chaos and unlock powerful marketing insights. Here are some key use cases.
Unified Cross-Channel Reporting
Marketers need to understand performance across all channels, from social media and search ads to email and offline events. A data fabric integrates all this data into a single, cohesive view.
This enables true cross-channel analysis and the creation of comprehensive KPI dashboards that reflect the entire marketing ecosystem. It moves beyond siloed channel reports to holistic performance measurement.
Real-Time Campaign Performance Monitoring
The speed of marketing requires real-time insights. A data fabric can ingest and process campaign data as it happens. This allows marketing teams to monitor performance, identify trends, and optimize campaigns on the fly.
This agility provides a significant competitive advantage, enabling teams to reallocate budget to what's working and quickly address underperforming tactics.
Advanced Marketing Attribution Modeling
Understanding which marketing touchpoints contribute to a conversion is a complex challenge. A data fabric provides the complete, unified dataset needed for sophisticated marketing attribution.
By connecting every interaction along the customer journey, businesses can move beyond simplistic first- or last-touch models to more accurate data-driven attribution, properly valuing each channel's contribution.
Customer Journey Analysis
Mapping the customer journey requires stitching together data from dozens of systems. A data fabric excels at this. It can link anonymous website visits to known leads in a CRM and eventually to purchasing customers in an e-commerce platform.
This complete view allows marketers to identify friction points, optimize conversion paths, and deliver more relevant experiences at every stage.
Predictive Analytics for Customer Churn
By combining historical customer behavior, engagement data, and support tickets, a data fabric can fuel predictive models. These models can identify customers who are at risk of churning. This allows marketing and customer success teams to intervene proactively with targeted retention campaigns, saving valuable revenue and improving customer lifetime value.
These use cases often rely on powerful business intelligence tools to visualize the insights derived from the data fabric.
Building a Data Fabric: A Step-by-Step Implementation Guide
Implementing a data fabric is a strategic journey, not a one-time project. It requires careful planning, the right technology, and a phased approach. Following these steps can help ensure a successful implementation that delivers tangible business value.
Step 1: Define Business Objectives and Use Cases
Start with the why. What specific business problems are you trying to solve? Identify 1-2 high-impact use cases to begin with. This could be creating a 360-degree customer view or enabling self-service analytics for the sales team. A clear focus ensures that your initial efforts deliver measurable results and build momentum for the broader initiative.
Step 2: Assess Your Current Data Architecture
You need to understand your starting point. Catalog your existing data sources, systems, and tools. Identify where your key data assets reside and how data currently flows between systems. This assessment will reveal the biggest pain points, such as data silos and quality issues, that the data fabric needs to address. It will also help you choose the right data fabric platform.
Step 3: Select the Right Data Fabric Platform & Tools
Not all data fabric solutions are created equal. Evaluate potential vendors based on their connectivity, metadata management capabilities, governance features, and scalability. Consider whether you want an end-to-end platform or prefer to assemble a best-of-breed solution from multiple components. A proof-of-concept (POC) with your top choice is highly recommended to validate its capabilities against your specific use cases.
Step 4: Design the Logical Data Fabric Architecture
With your tools selected, it's time to design the architecture. This involves defining how the various components will work together. You'll map out data ingestion patterns, define your metadata model, and establish your global governance policies. This is the blueprint for your data fabric. It should be designed for flexibility and scalability from the outset.
Step 5: Implement Core Components (Metadata, Governance)
Begin by implementing the foundational elements of your fabric. This usually means setting up the data catalog and knowledge graph. Start connecting data sources to populate the catalog with active metadata. At the same time, define and configure your initial set of data governance rules and access control policies. This core infrastructure is essential before you open up access to users.
Step 6: Connect Data Sources Incrementally
Don't try to boil the ocean. Start by connecting the data sources required for your initial high-priority use cases. Onboard these sources, ensure the data is profiled correctly, and apply the necessary quality and governance rules. This iterative approach allows you to demonstrate value quickly and learn as you go.
Step 7: Empower Users with Self-Service Tools
Once you have a critical mass of trusted, well-documented data in the fabric, you can start onboarding users. Provide training on the self-service tools for data discovery and access. Promote the data catalog as the single source of truth for finding data. Gather feedback from early adopters to refine the user experience and the available data products.
Step 8: Monitor, Optimize, and Iterate
A data fabric is a living system. Continuously monitor its performance, data quality, and user adoption. Use the insights from the fabric's own operational metadata to identify bottlenecks and opportunities for optimization. As the business evolves, you will continue to add new data sources and develop new use cases, expanding the reach and value of your data fabric over time.
Data Fabric Platforms and Solutions: What to Look For
Choosing the right technology is critical for a successful data fabric implementation. A data fabric platform is a comprehensive software solution that provides the core capabilities needed to build and manage a data fabric. When evaluating different data fabric solutions, there are several key features to consider.
Comprehensive Connectivity
The platform must be able to connect to all your data sources, wherever they are. Look for a wide range of pre-built connectors for databases, data warehouses, cloud applications, streaming platforms, and data lakes. The ability to handle diverse data types (structured, semi-structured, unstructured) and ingestion methods (batch, real-time) is essential.
Active Metadata Management
This is the engine of an intelligent data fabric. The platform should have strong capabilities for automatically discovering, profiling, and classifying data. Look for an AI-powered knowledge graph that can infer relationships, track data lineage, and provide business context. The metadata should be used to actively drive automation and recommendations within the platform.
Robust Security and Governance Features
The platform must provide a centralized way to manage data governance and security. Key features include role-based access control, data masking for sensitive information, and policy-based automation. The ability to create and enforce data quality rules is also crucial. The platform should provide a complete audit trail of all data access and modifications to ensure compliance. You might consider specific data integration solutions that specialize in governance.
Scalability and Performance
A data fabric needs to handle large volumes of data and a high number of concurrent users. The platform's architecture should be scalable, capable of running in a distributed environment. It should use advanced query optimization and caching techniques to deliver high performance, whether it's using data virtualization or physical data movement.
Support for AI and Machine Learning
Modern data fabrics are not just for traditional BI. They should support the entire analytics lifecycle, including AI and machine learning. The platform should make it easy for data scientists to find and access training data. It should also integrate with popular MLOps tools for model development and deployment. Some platforms even have built-in capabilities for building and running machine learning models.
Common Challenges in Data Fabric Implementation (And How to Solve Them)
While a data fabric offers immense benefits, the implementation journey is not without its challenges. Being aware of these potential hurdles can help you plan for them and increase your chances of success.
Cultural Resistance to Data Sharing
Challenge: Departments are often protective of their data, viewing it as their own asset. This "data hoarding" mentality can be a major barrier to creating a unified data fabric.
Solution: Overcome this with strong executive sponsorship and clear communication about the benefits of data sharing for the entire organization. Start with a federated governance model that gives domains some control over their data while still making it available through the fabric. Highlight early wins to demonstrate the value of collaboration.
Technical Complexity and Integration Hurdles
Challenge: Integrating hundreds of diverse, and often legacy, systems can be technically complex. Each system has its own format, API, and access method.
Solution: Choose a data fabric platform with a robust and extensive library of pre-built connectors. Adopt an incremental approach. Start with the most critical and modern systems first to build momentum. For legacy systems, use a combination of data virtualization and targeted data migration strategies.
Ensuring Data Quality Across Sources
Challenge: When you bring data together from multiple sources, you also bring together all of their quality issues. Inconsistencies and errors can erode trust in the data fabric.
Solution: Make data quality a core part of your data governance strategy. Use the data fabric platform to automatically profile data and identify quality issues at the source. Implement data quality rules that can cleanse and standardize data as it enters the fabric. Appoint data stewards for key data domains to be responsible for data quality.
Managing Costs and Proving ROI
Challenge: Implementing a data fabric can be a significant investment in software, infrastructure, and skilled personnel. It can be difficult to justify the cost without a clear return on investment (ROI).
Solution: Start with a clear business case tied to specific, measurable outcomes. For example, aim to reduce reporting time by 50% or increase marketing campaign ROI by 10%. Track these metrics closely and communicate successes to stakeholders. Consider a cloud-based data fabric solution to reduce upfront infrastructure costs.
The Role of AI and Machine Learning in a Modern Data Fabric
Artificial intelligence and machine learning are not just consumers of data from the fabric; they are also integral components that make the fabric intelligent and autonomous. AI/ML is woven throughout the architecture to automate complex tasks and enhance capabilities.
Automating Metadata Discovery and Tagging
Manually documenting and tagging thousands of data tables is an impossible task. AI algorithms can scan the content and structure of data assets to automatically infer business context. They can identify personally identifiable information (PII), classify data by subject area (e.g., "customer," "product"), and suggest business glossary terms. This automates the creation of a rich, searchable data catalog.
Anomaly Detection in Data Pipelines
Data pipelines can be fragile. Machine learning models can learn the normal patterns of your data flows, volume, velocity, and schema. They can then monitor these pipelines in real-time and automatically flag any anomalies.
For example, a sudden drop in the number of records from a key source could indicate a problem that requires immediate attention. This proactive monitoring ensures data reliability and is a cornerstone of powerful reporting automation.
Recommending Datasets to Users
Just like Netflix recommends movies, a smart data fabric can recommend datasets to users. By analyzing a user's role, their query history, and the behavior of similar users, the fabric's AI engine can proactively suggest data assets that are likely to be relevant. This "data shopping" experience accelerates data discovery and helps users find valuable data they didn't even know existed.
Optimizing Query Performance
An AI-powered data fabric can optimize its own performance. It can analyze query patterns and automatically decide whether to use data virtualization, create a materialized cache, or recommend a new index. It learns which data is accessed most frequently and pre-optimizes it for fast delivery. This self-tuning capability ensures that the data fabric remains performant as workloads change and data volumes grow.
How Improvado Powers Your Marketing Data Fabric
For marketing organizations, Improvado provides a powerful platform that acts as the core of a specialized marketing data fabric. It is designed to solve the unique data challenges faced by modern marketing teams, delivering a unified, analysis-ready view of all marketing and sales activities.
Automated Data Extraction and Loading
Improvado offers 1,000+ pre-built connectors to every marketing, sales, and analytics platform you use. This comprehensive connectivity automates the most time-consuming part of data integration.
Data is extracted and loaded into a centralized destination of your choice, such as Google BigQuery, Snowflake, or Amazon Redshift, forming the foundation of your fabric.
Data Transformation for Analysis-Ready Insights
Raw data from marketing platforms is often messy and inconsistent. Improvado's transformation layer cleans, normalizes, and maps data from different sources into a unified data model.
- Transform & Model Capabilities: Improvado centralizes data from over 500 sources and applies consistent taxonomies, rules, and business logic at scale. Teams can create reusable, modular transformation workflows that ensure uniform data structures across brands, regions, and campaigns — without heavy reliance on engineering teams.
- AI-Powered Transformation Agents: With Improvado’s AI Agent for Transformation, repetitive tasks like mapping, normalization, and enrichment are automated. The AI suggests transformations, detects anomalies, and flags discrepancies, reducing manual workload and accelerating time-to-value.
- Built-In Governance and Security: The platform includes strict version control, audit trails, and data lineage tracking. These features give enterprise teams confidence that transformed datasets are accurate, compliant, and secure — critical for scaling operations across multiple markets and regulatory environments.
Seamless Integration with BI and Reporting Tools
The data prepared by Improvado can be seamlessly pushed to any business intelligence tool, such as Tableau, Looker Studio, or Power BI. This allows marketing analysts and leaders to build the comprehensive dashboards and reports they need, all powered by the unified data from the Improvado-driven data fabric. It accelerates the entire cycle from data collection to insight delivery.
Conclusion
The era of fragmented data and siloed analytics is coming to an end. The complexity of the modern data landscape demands a more intelligent, agile, and unified approach. A data fabric provides that solution. It is the architectural paradigm that allows organizations to finally harness the full potential of their data assets, no matter where they are located.
By creating an intelligent layer that connects, governs, and delivers data, a data fabric empowers every user in the organization. It accelerates decision-making, strengthens governance, and provides the scalable foundation needed for advanced analytics and AI.
For marketers, a data fabric is the key to unlocking a true 360-degree view of the customer and proving the ROI of their efforts. Adopting a data fabric is no longer a technical choice; it is a strategic business imperative for any organization that wants to thrive in the digital age.