Data Extraction - Best practices
Overview
This document provides comprehensive best practices for creating, managing, and optimizing reports in Improvado. It is designed to help users from setting up their initial reports to ensuring ongoing data integrity and performance optimization.
The main principles of effective report configuration
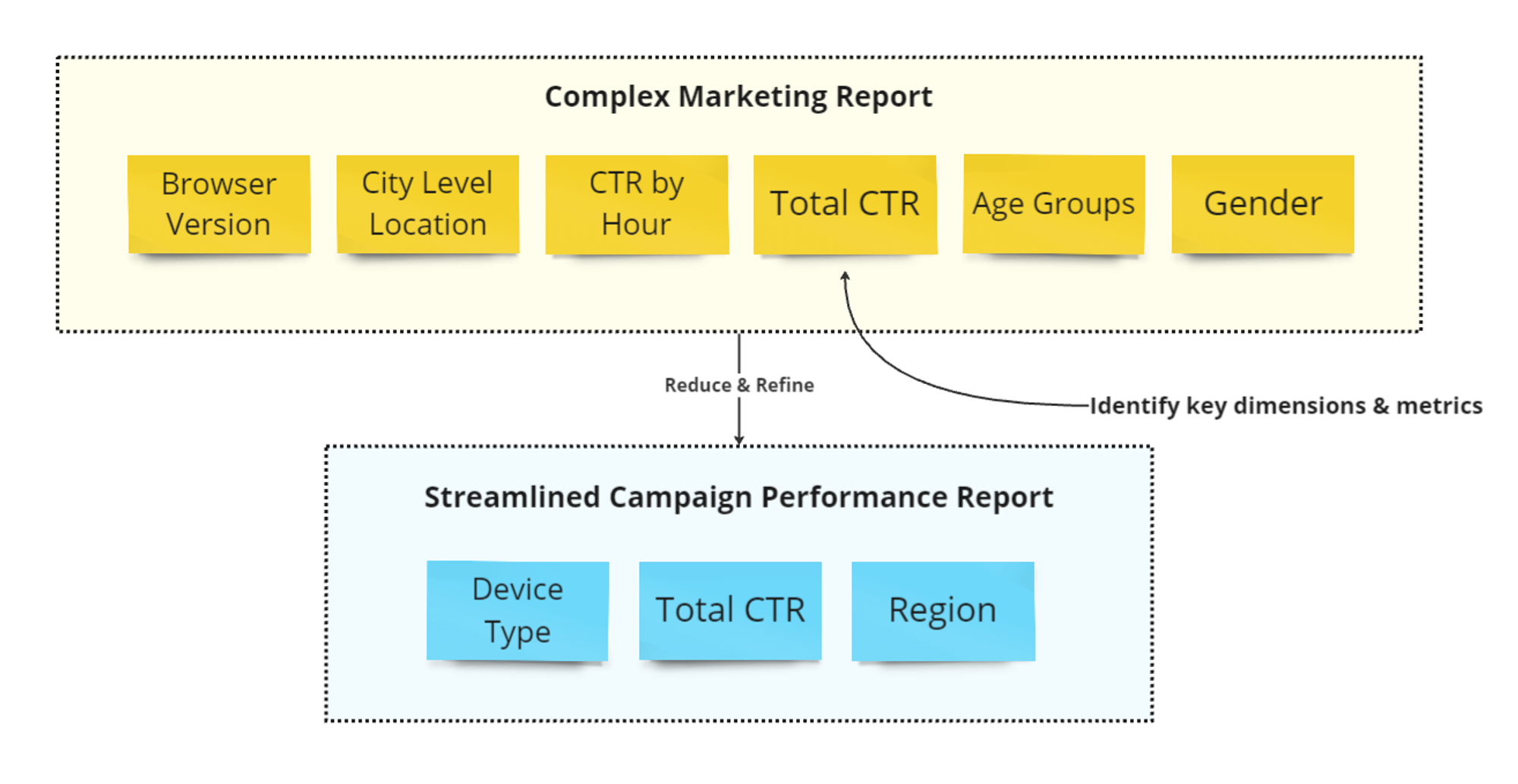
- Simplification of Reports: Emphasize clarity by reducing the number of report elements, focusing on essential data only.
- Avoiding High Cardinality Dimensions: Limit the use of dimensions with a large number of unique values to enhance report performance and readability.
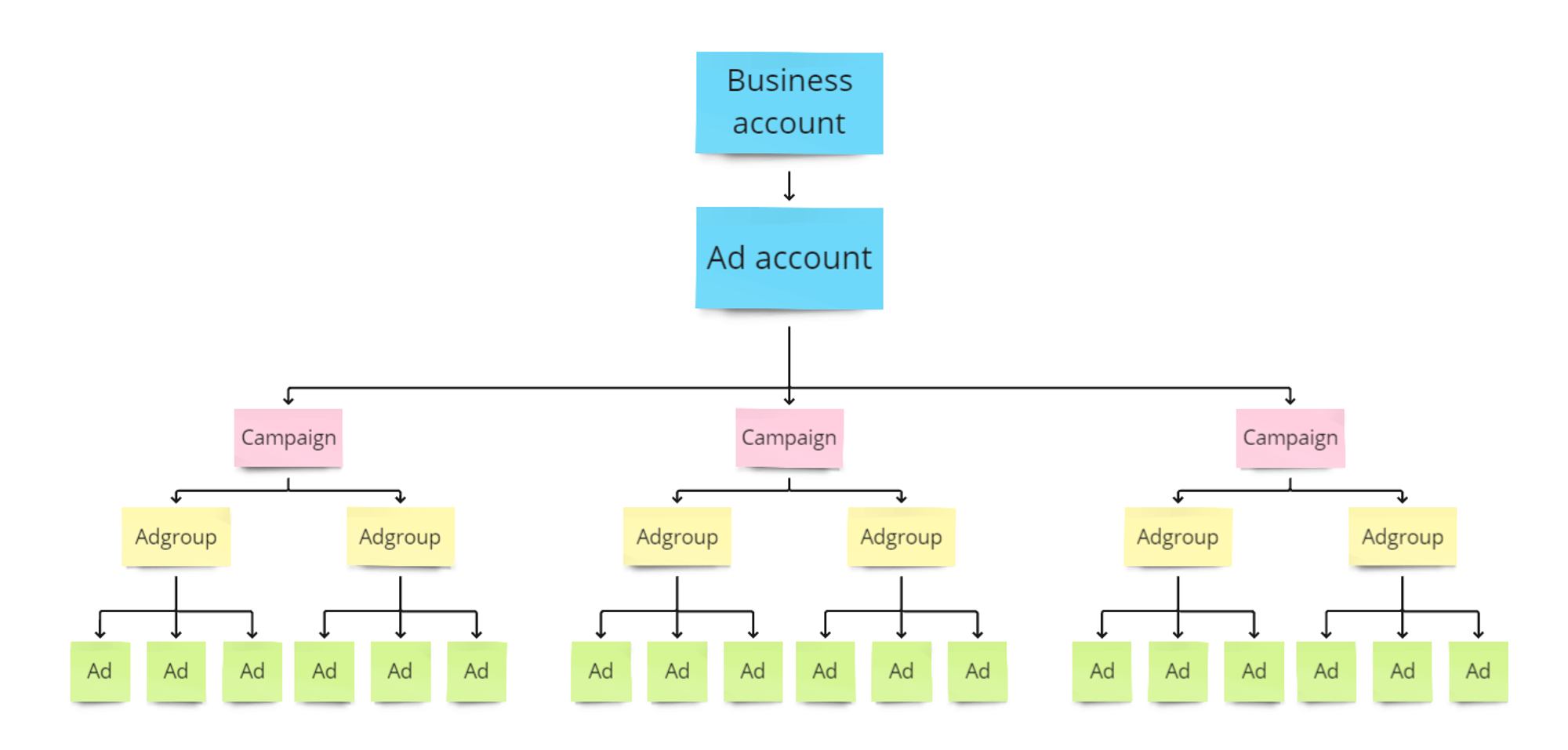
- Optimizing Report Structures for Similar Accounts: Avoid creating duplicate or highly similar report structures for the same accounts. This practice can lead to an increased number of orders for data processing. Instead, find a balance between highly granular reports and having 2-3 reports where the only differences are one or two dimensions.
- Balancing Data Granularity and Aggregation: Determine the optimal level of detail versus aggregated data to meet analysis needs without compromising performance.
Recommendations for building reports in Improvado
- Separate granular and aggregated data: If you need granular values and aggregated values, then it’s better to create separate reports for granular data and aggregated values.
- Utilize atomic granularity for precise comparisons: Use the smallest level of detail for critical data comparisons to ensure accuracy.
- Replicate data structures from the Data provider’s platform: Follow structured steps to accurately mirror the data setup in Improvado, ensuring consistency and reliability in reports.
- Avoid overly granular reports: Identify key metrics and dimensions that directly relate to your reporting goals. Limit your report to include only those elements that will provide you with actionable insights.
- Optimize Data Extraction schedules: Set data extractions during off-peak hours to improve performance and reduce system load.
- Streamline Reports for Efficiency: Avoid creating identical or very similar structures for the same accounts, as this can increase the number of processing operations for the same data.
Case studies
User created a very detailed Extraction which resulted in a slowed-down processing speed due to a large volume of data (3M+ rows per day)
- Case: User attempted to extract every possible dimension and metric available from their sales data across multiple regions. The extraction included detailed transaction times, customer demographics, and individual product IDs. Such exhaustive data capturing led to a significant increase in extraction times and processing load.
- Solution:
- Review your reporting requirements and identify the necessary dimensions that are essential for achieving your analysis objectives. Focus on those that directly impact decision-making or performance measurement.
- Avoid dimensions with a high number of unique values (high cardinality), as they significantly increase the complexity and processing times of your data extractions. Determine if high cardinality dimensions can be aggregated into broader categories without losing critical insights.
User has performance concerns with processing 200+ million rows, which is taking more than 4 hours.
- Case: Extracted data was processed from a global marketing campaign involving multiple metrics such as click rates, engagement rates, and demographic information from several platforms. The complexity and volume of data processed exceeded the system's optimal performance threshold.
- Solution:
- Make sure that you have the right expectations based on data volume and granularity. Assess the total number of rows and the complexity of the data including the number of dimensions and metrics. Larger datasets and more complex queries generally require longer processing times.
User scheduled their data extraction at 1 AM ET, with processing duration varying between 10 minutes to 1:30 hours causing discrepancies in the extracted data vs. the Data Provider’s UI
- Case: User set an automated extraction from a financial reporting platform without considering the time zone impact or the data generation cycle of the source system. Variations in extraction times coupled with timing misalignment led to inconsistent data retrieval.
- Solution:
- Setting a specific time zone can impact the availability of data and the accuracy of your reports. You’ll need to carefully select the time zone for your Extraction. Delays are a common occurrence and should be anticipated.
- Schedule data extractions during low-activity periods to optimize system performance and minimize delays.
- If consistent delays occur, consider adjusting the schedule or frequency of the extractions to better align with system capabilities and data needs.