Group Data
The Group Data operator is an addition to Self-Serve Data Transformation, designed to aggregate and organize your data at the transformation layer. Whether you need to simplify complex joins or clean up data for downstream operations, Group Data provides a structured way to manage large and fragmented datasets during the transformation process.
How Does It Work?
- Select a Table and Target
- This step determines the scope of the Group Data operation. You need to specify which table and which result within your transformation flow will be grouped. You can apply it for any table you have or any previous result in the transformation flow.
- Choose Grouping Dimensions
- Grouping dimensions are the fields by which the data will be aggregated. These could be categorical fields that define the logical grouping of your data. You also can select multiple dimensions to create more granular groupings.
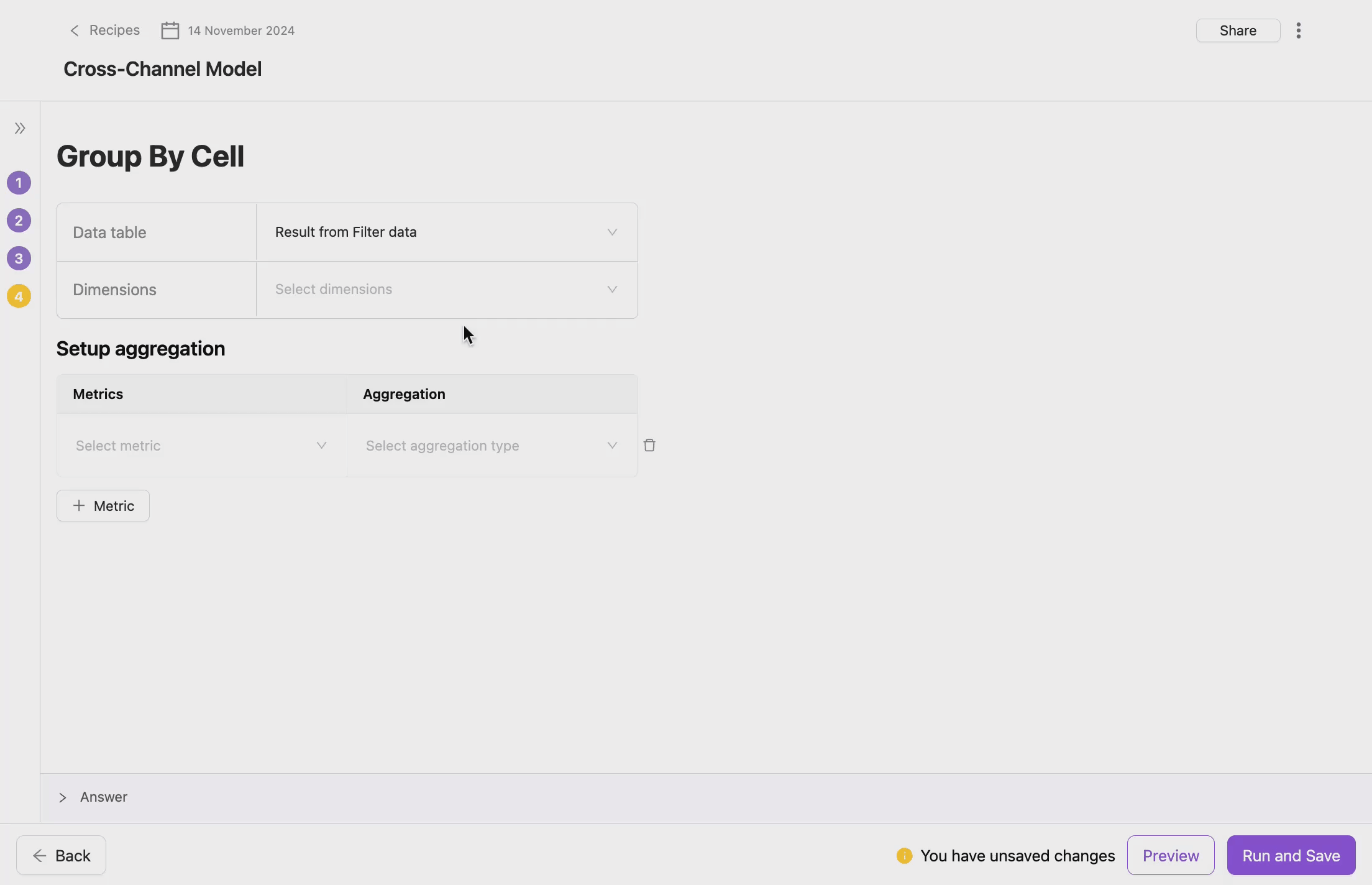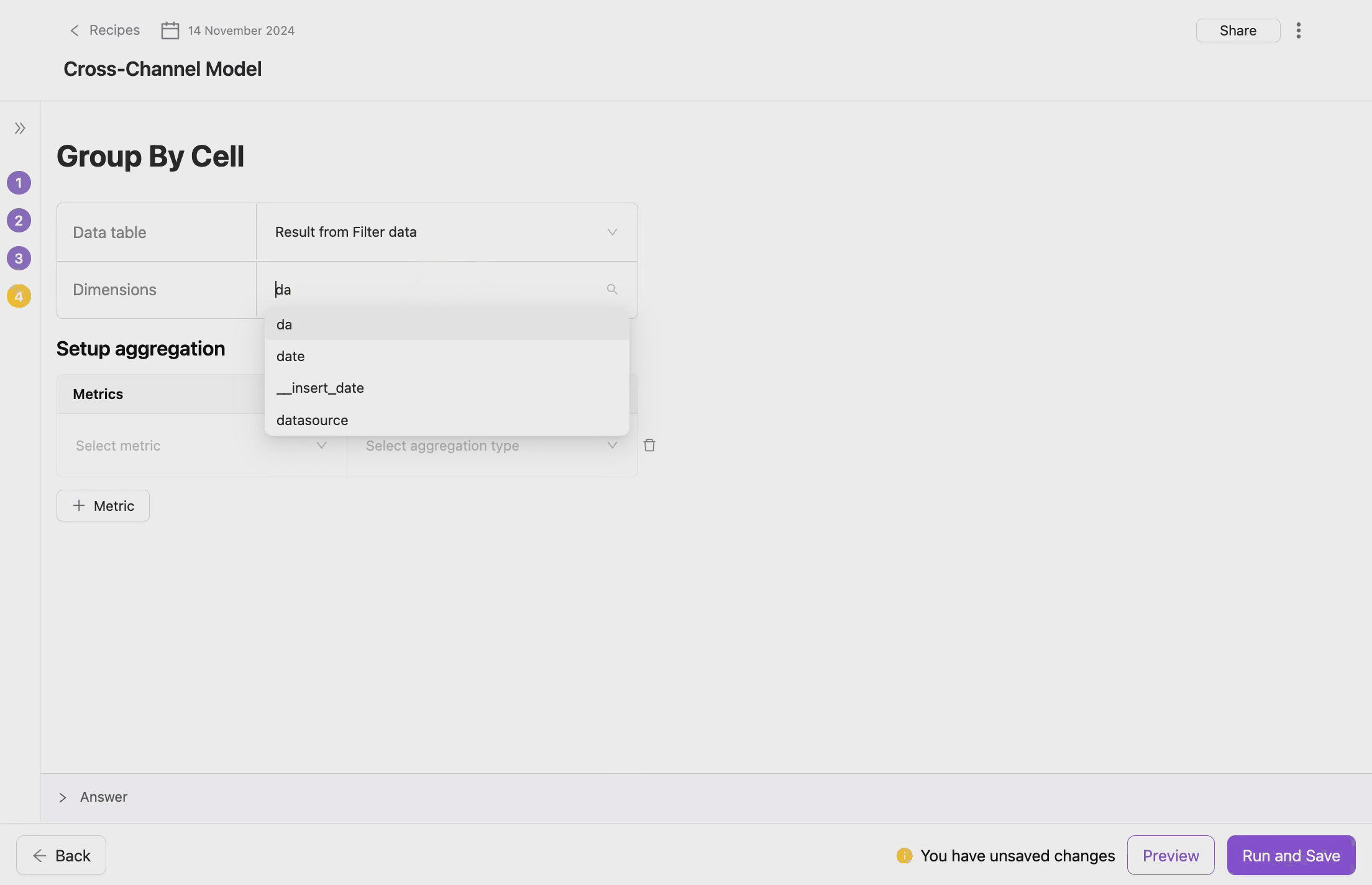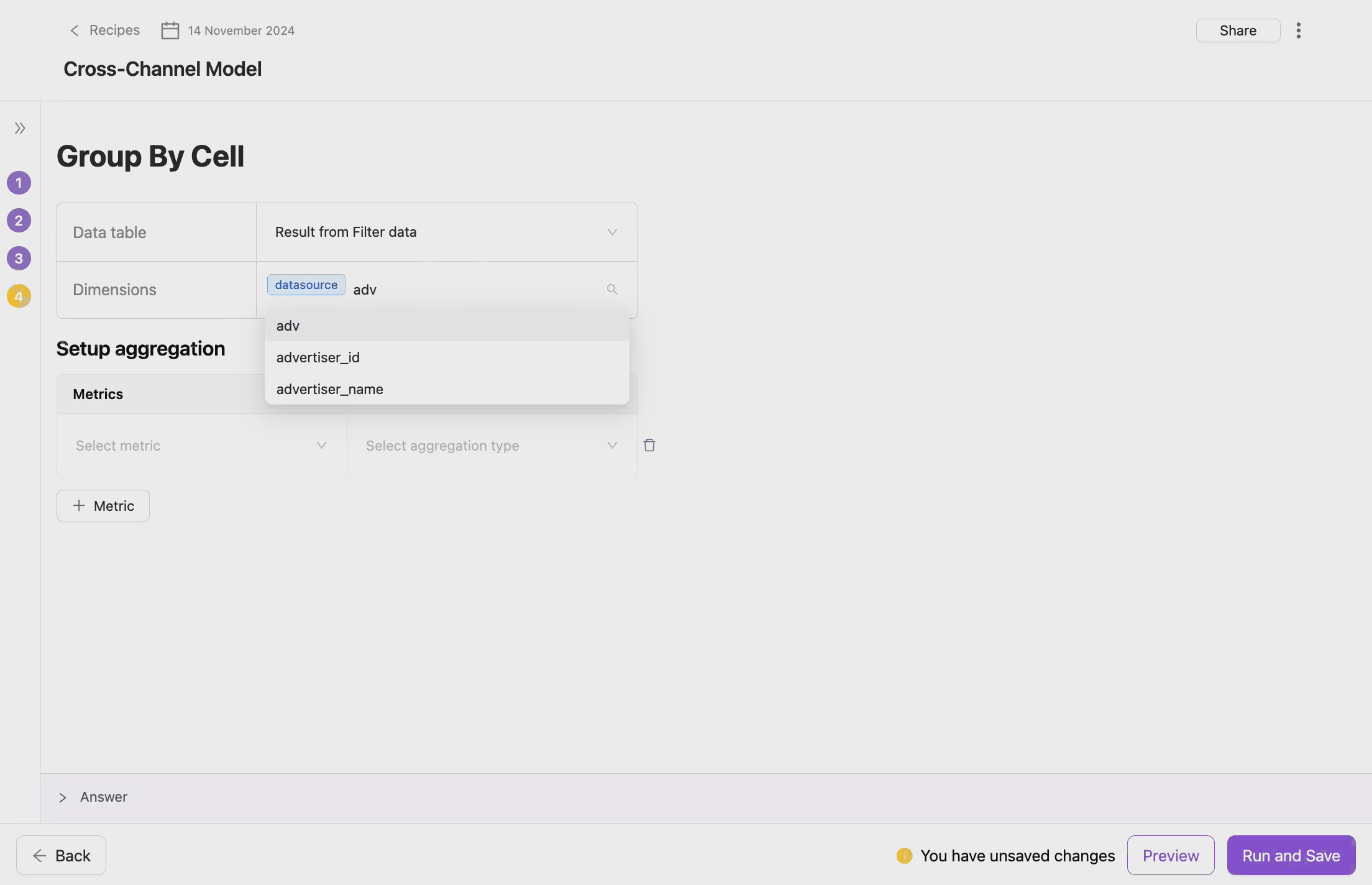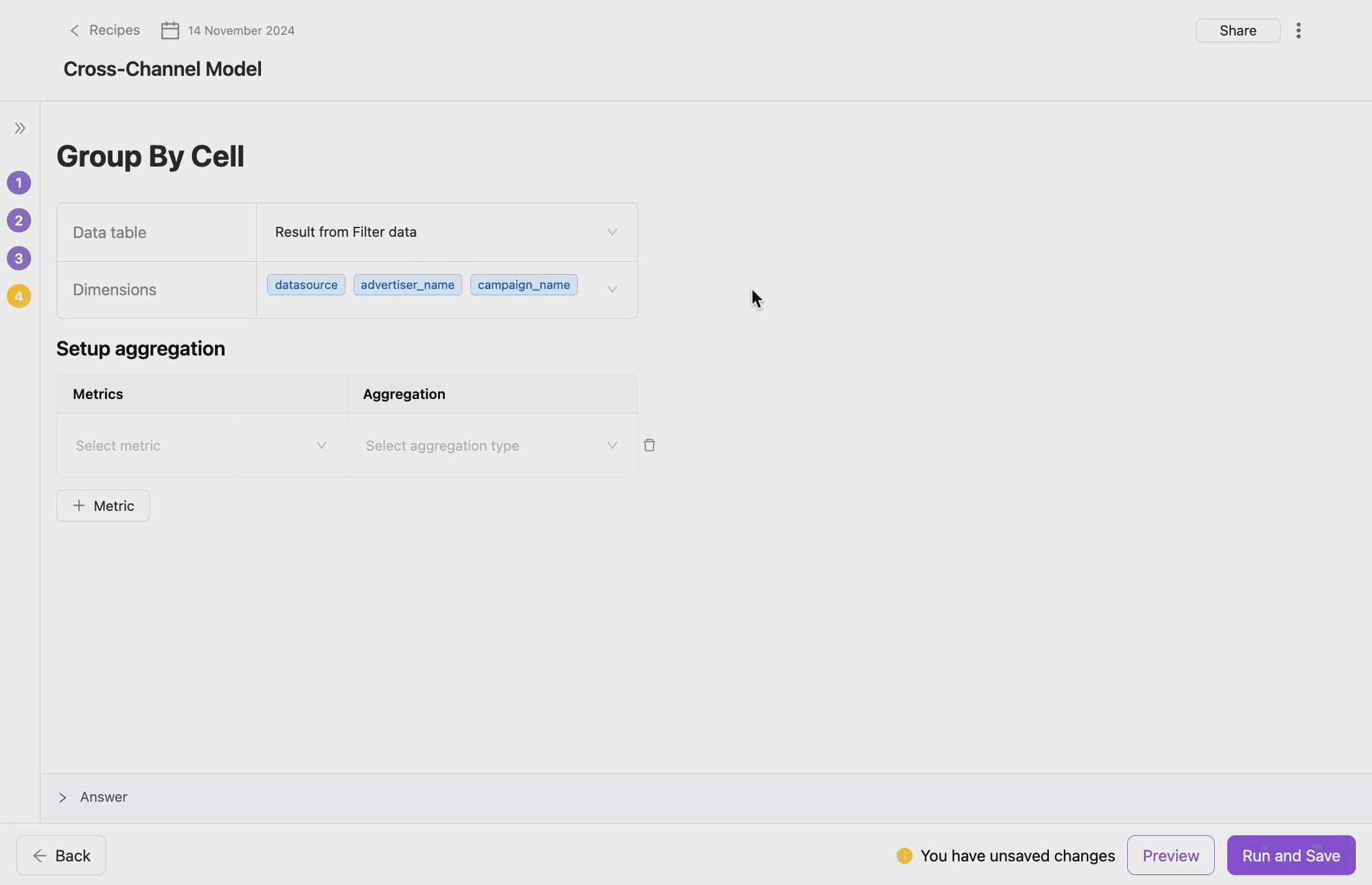
- Select Metrics for Aggregation
- Metrics are numerical fields that are aggregated during the Group Data operation. You can apply different aggregation functions (e.g., sum, average, count) to each metric.
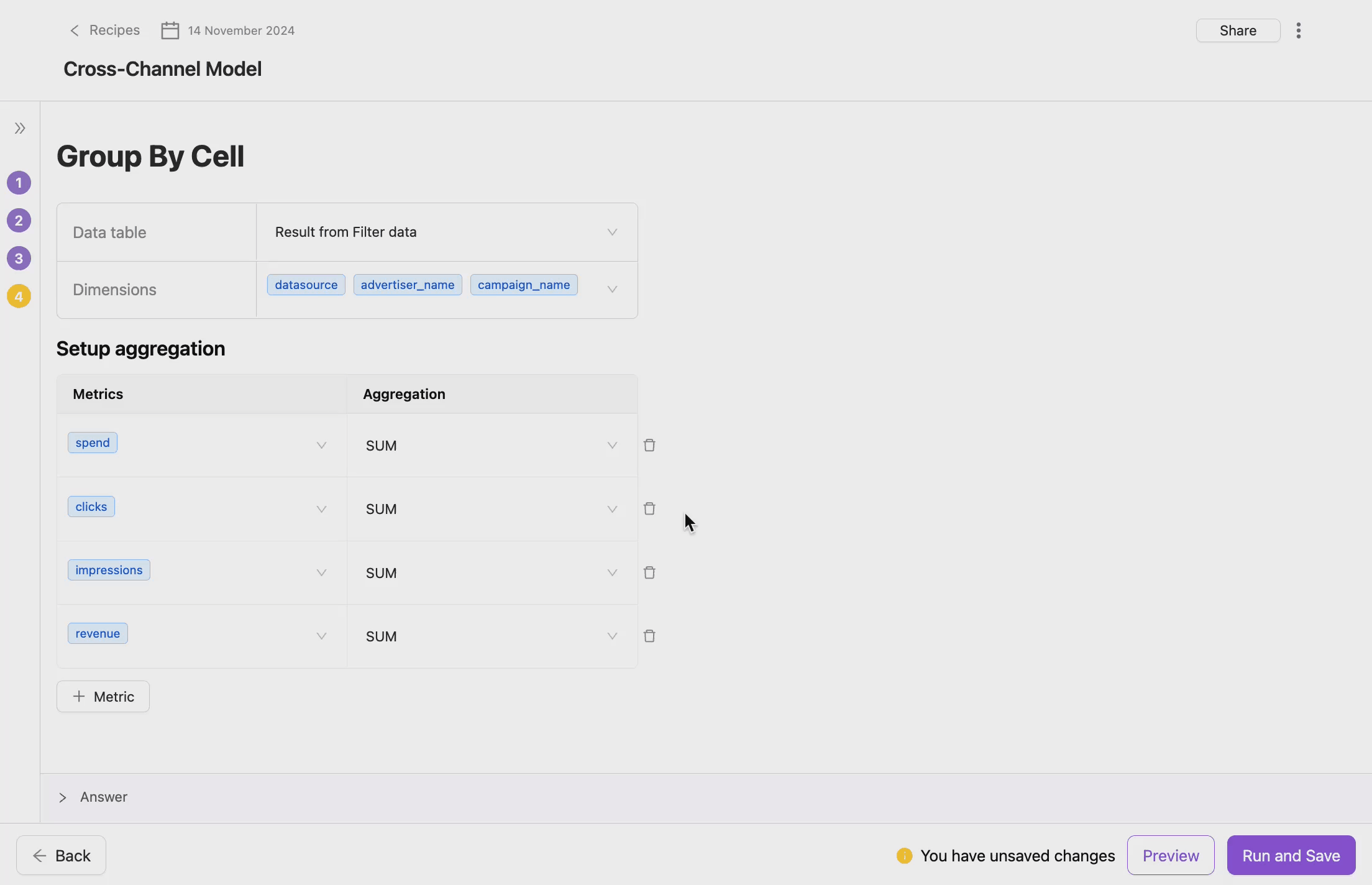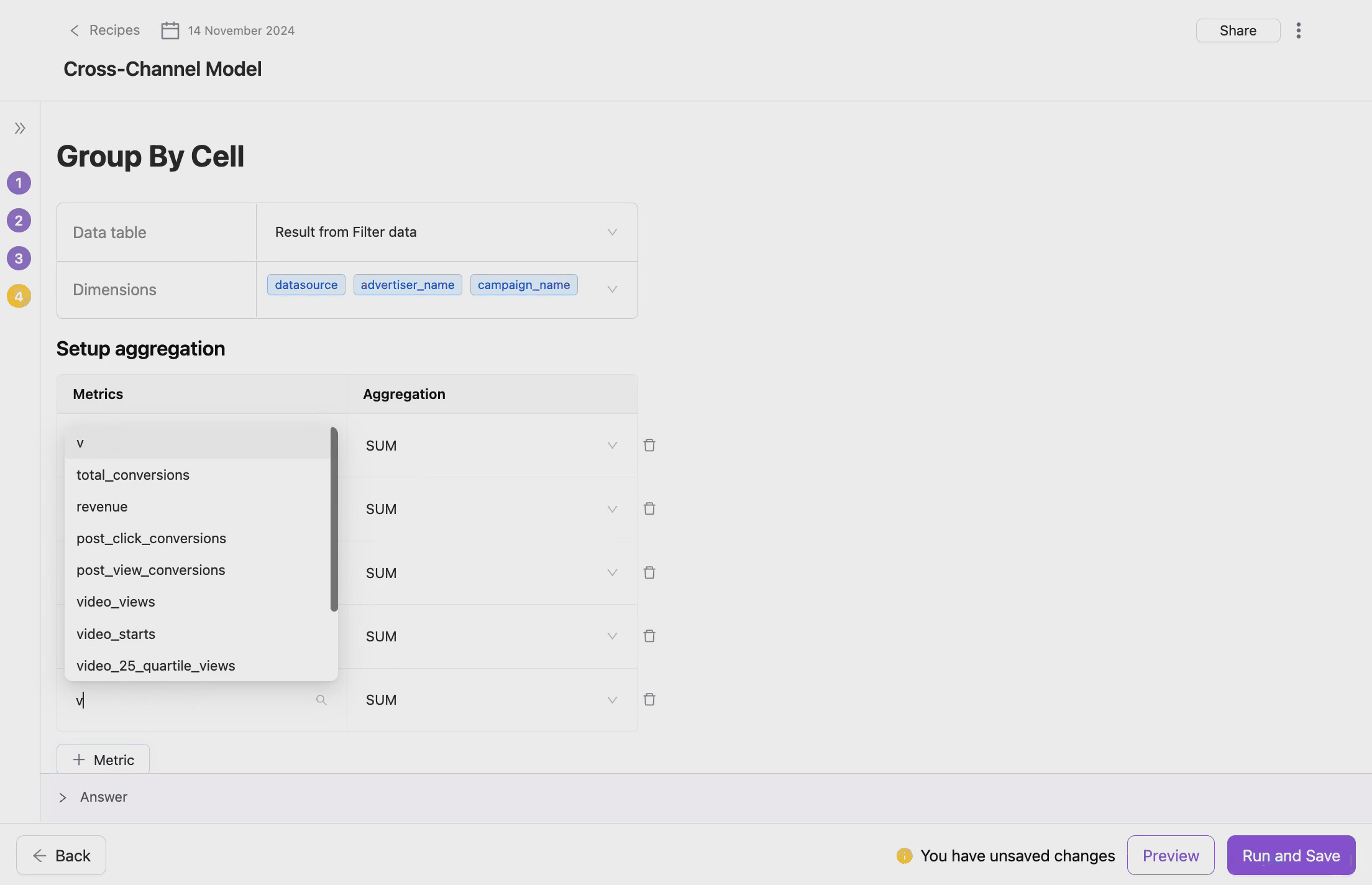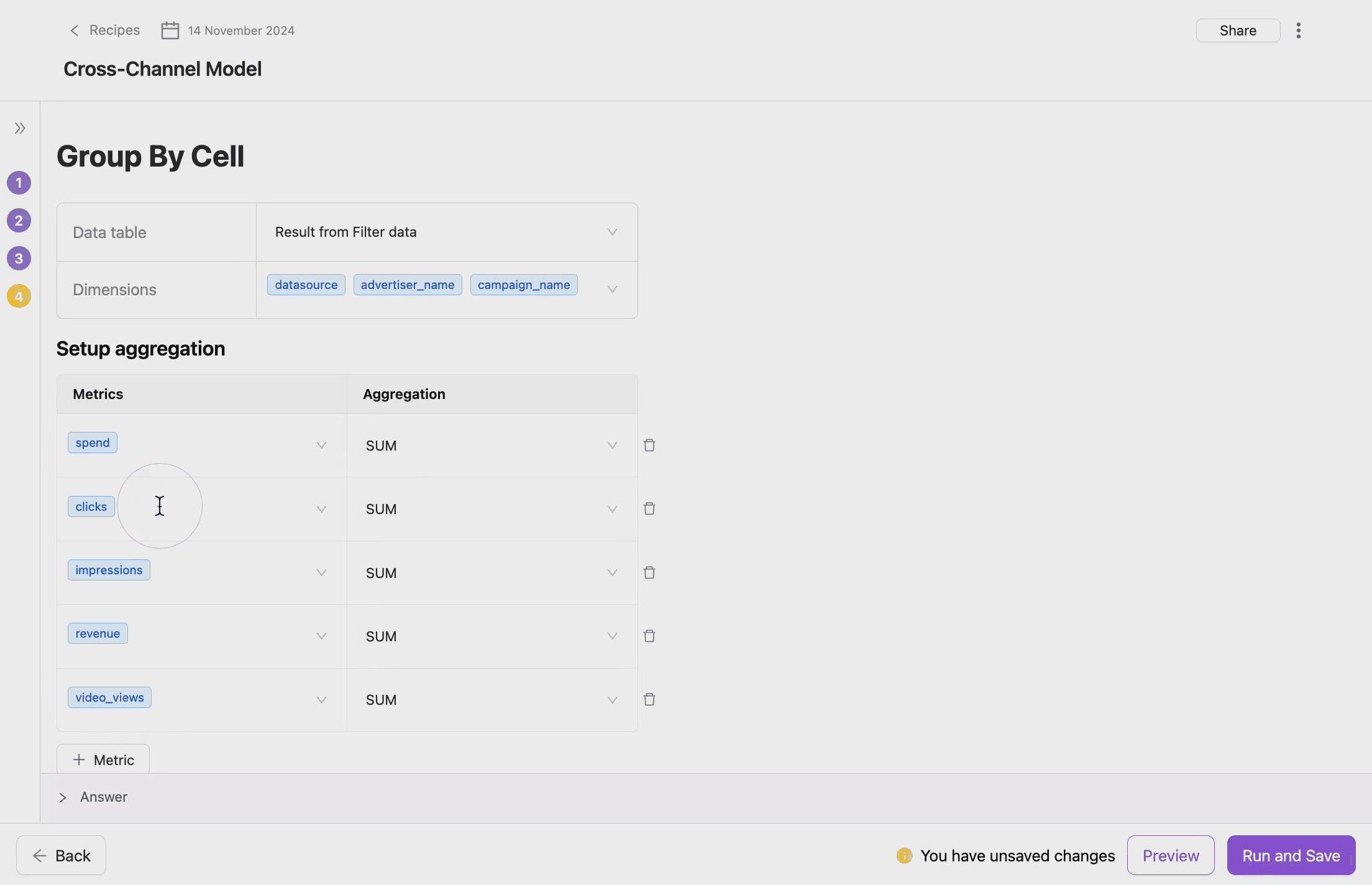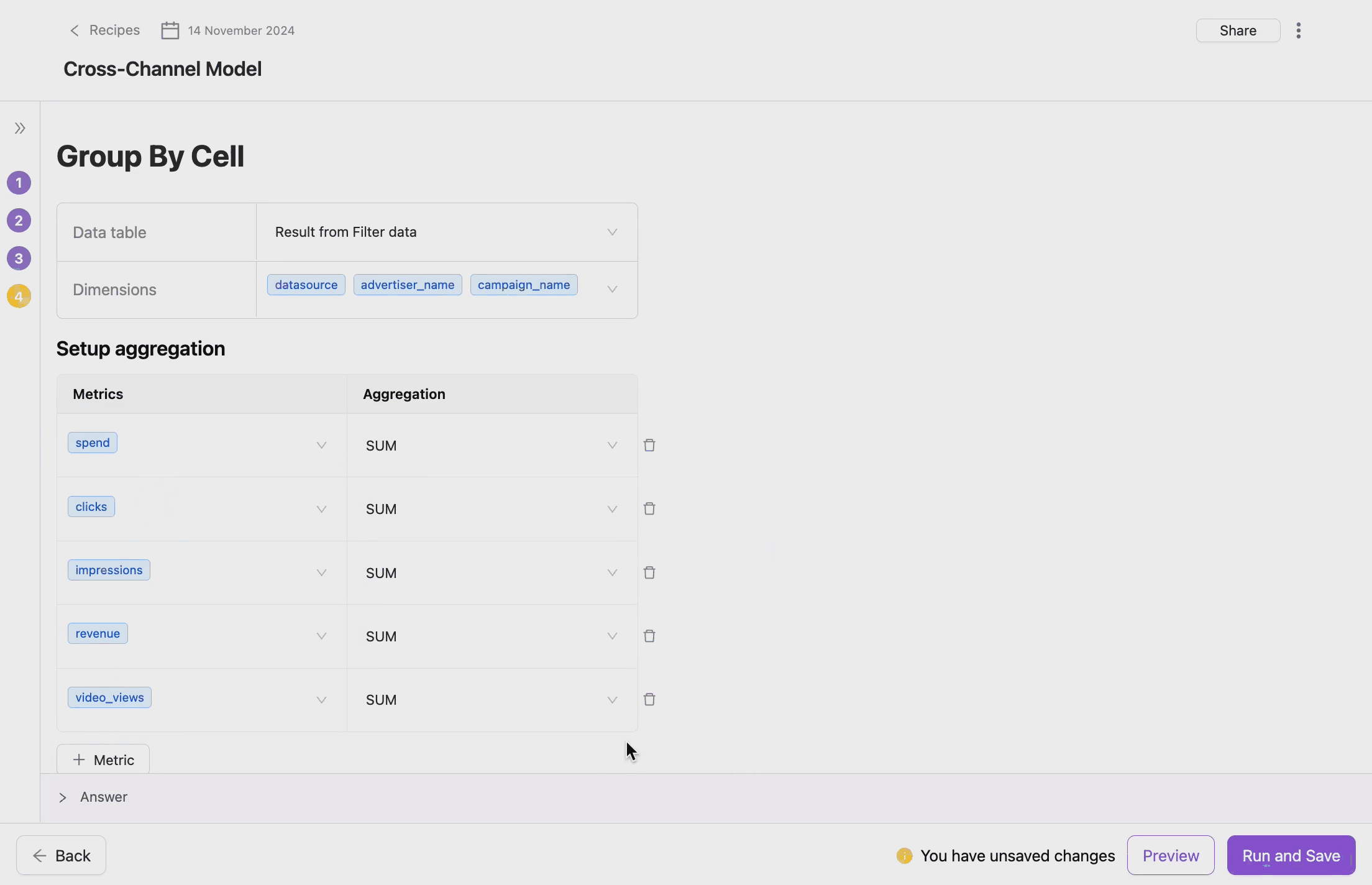
- Define Aggregation Type
- This step allows you to define how numerical fields (metrics) are aggregated.
In addition to basic aggregations, custom aggregation provides extensive flexibility: each metric can have a different aggregation type:
- SUM
- COUNT
- COUNT DISTINCT
- MIN
- MAX
- AVG
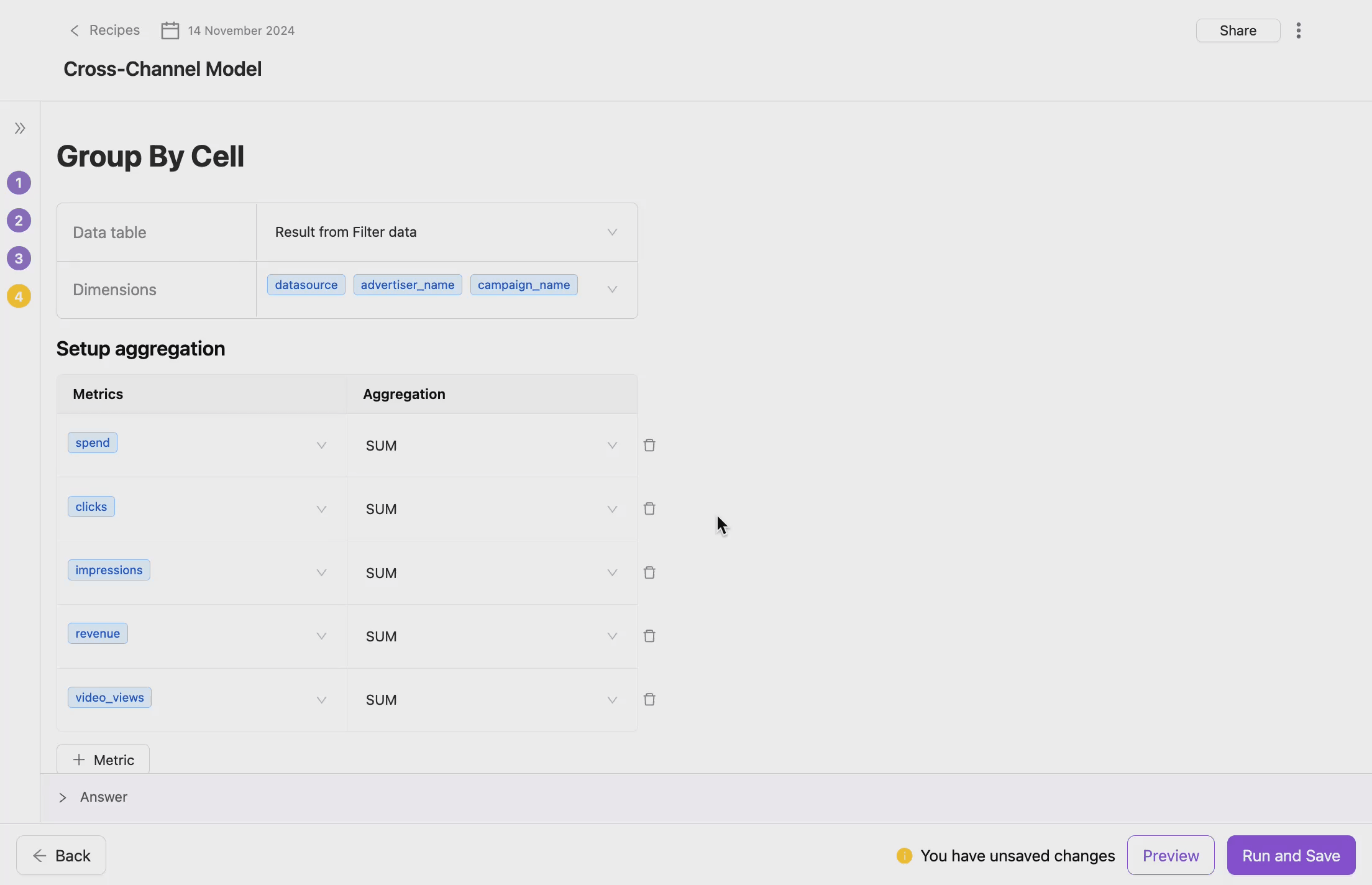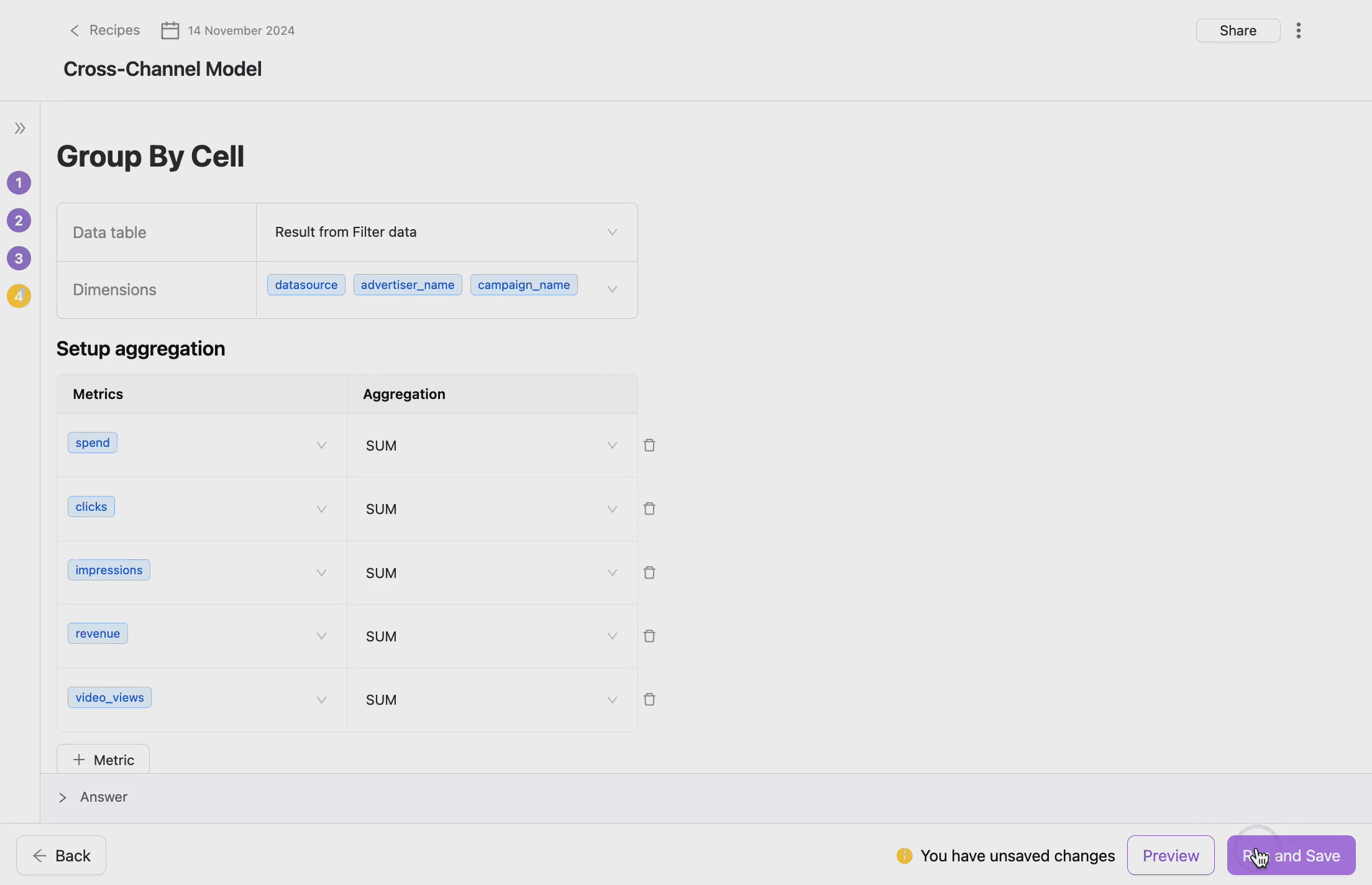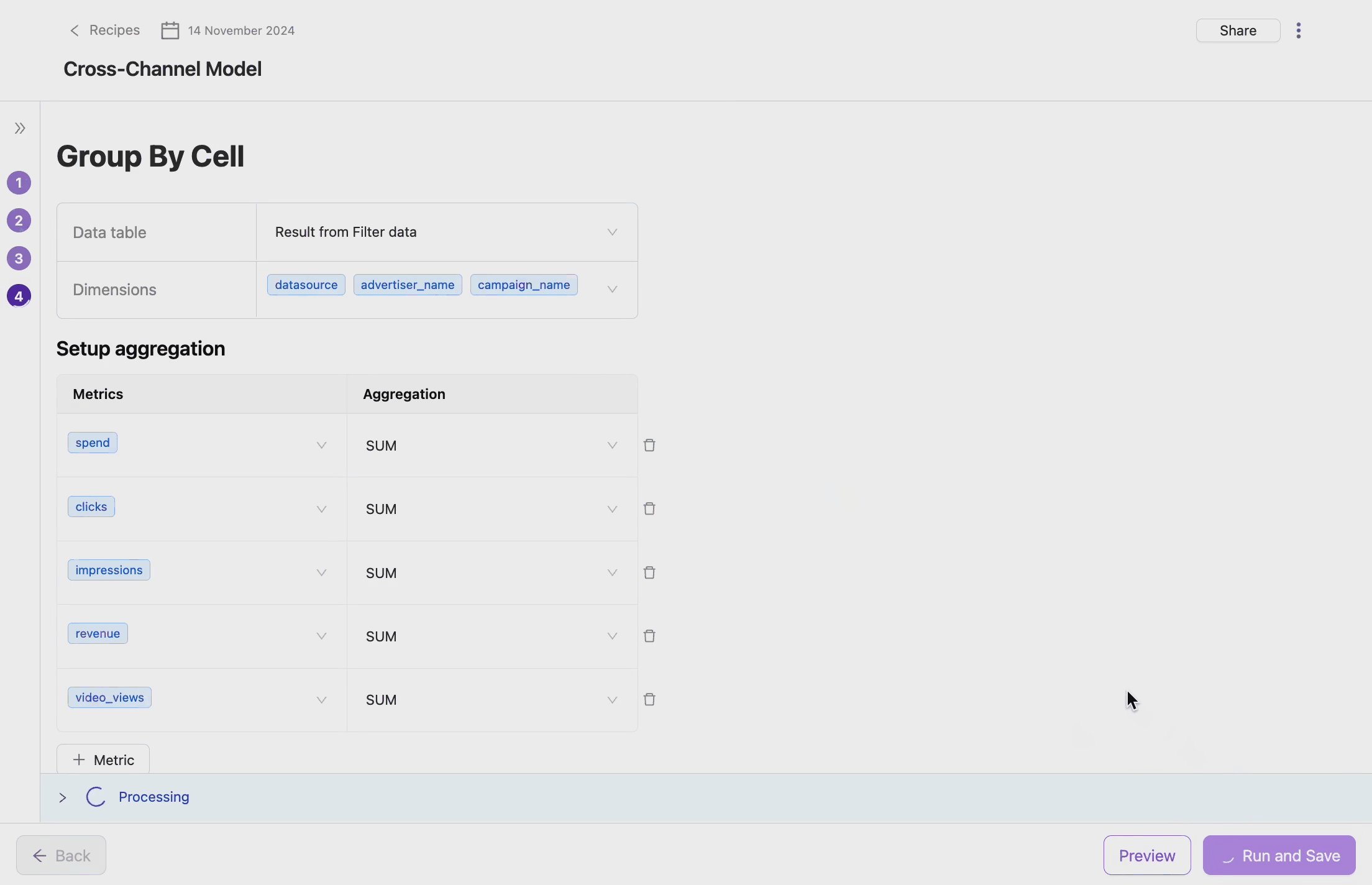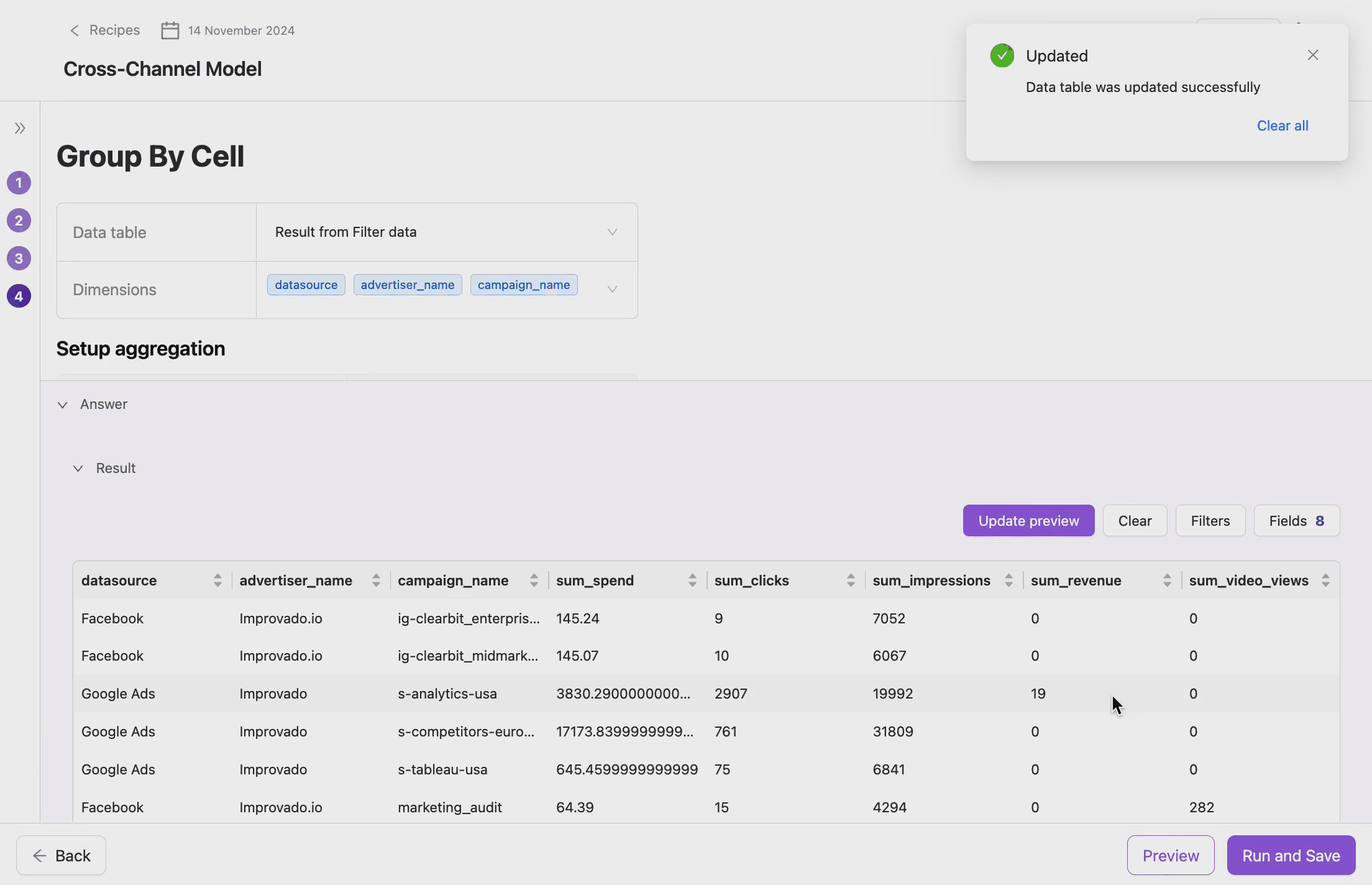
- Update the model.
- Once the transformation is done, you can apply it to the model by clicking the Run and Save button.
Use Cases
Group Data is invaluable in Data Transformation workflows where raw data needs to be cleaned, merged, or restructured to create cohesive and meaningful models.
Here are key use cases for Group Data in Data Transformation:
Data Cleanup and Normalization
Remove duplicate records, normalize fragmented data, and aggregate metrics.
Example
You can consolidate multiple rows of raw data into a single entry by summing up metrics like Spend or Impressions.
Post-Join Aggregation
Eliminate duplicate rows caused by joins, ensuring a clean dataset with unique keys.
Example
After joining Ad Group Data and Account Details, sum Clicks and Revenue for each Ad Group ID and Account Name to remove duplicate rows.
Hierarchy Consolidation
Simplify working with hierarchical data by rolling up metrics to a higher level.
Example
In datasets with "Brand > Product > SKU" levels, group metrics like sales and revenue at the brand level to understand overall performance without breaking down individual SKUs.
Input Preparation for Advanced Calculations
Group Data aggregates data to prepare it for calculations.
Example
Group revenue and expenses at the customer level to compute margins or ROI for each customer in the next stage of analysis.
Conclusion
By supporting custom aggregations and flexible configurations, the Group Data operator provides a robust tool for handling complex Data Transformation workflows, empowering users to create clean and actionable models.
Was this article helpful?
Thanks for the feedback!