Custom query for SQL Flat Data
Custom SQL queries allow you to shape, filter, and optimize your data. Now, instead of pulling entire tables, you can write your query directly in the flat data extraction flow. This gives you more control to pre-filter or group your data before extraction, speeding up the process and reducing unnecessary load.
How to use the Custom SQL query
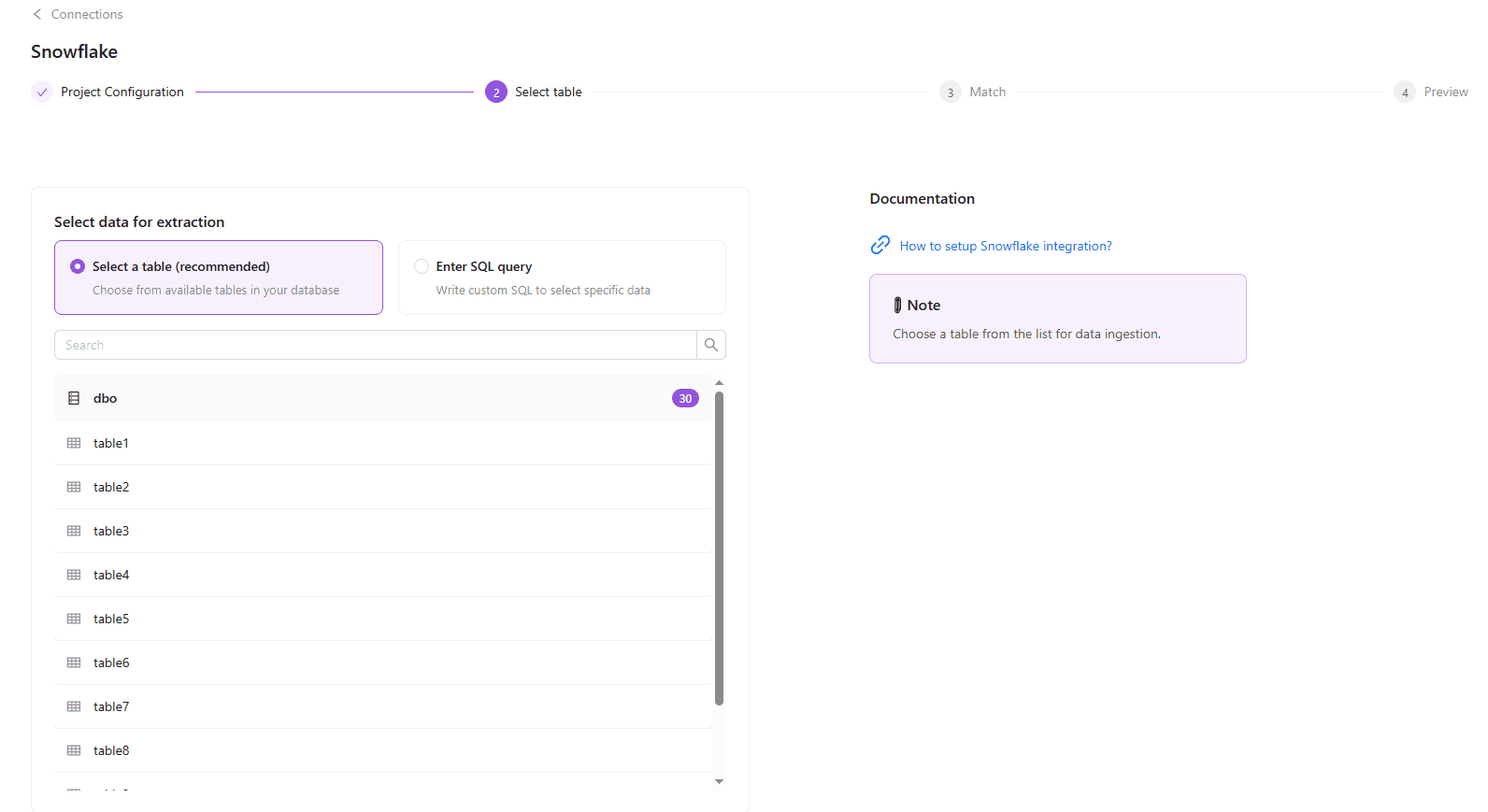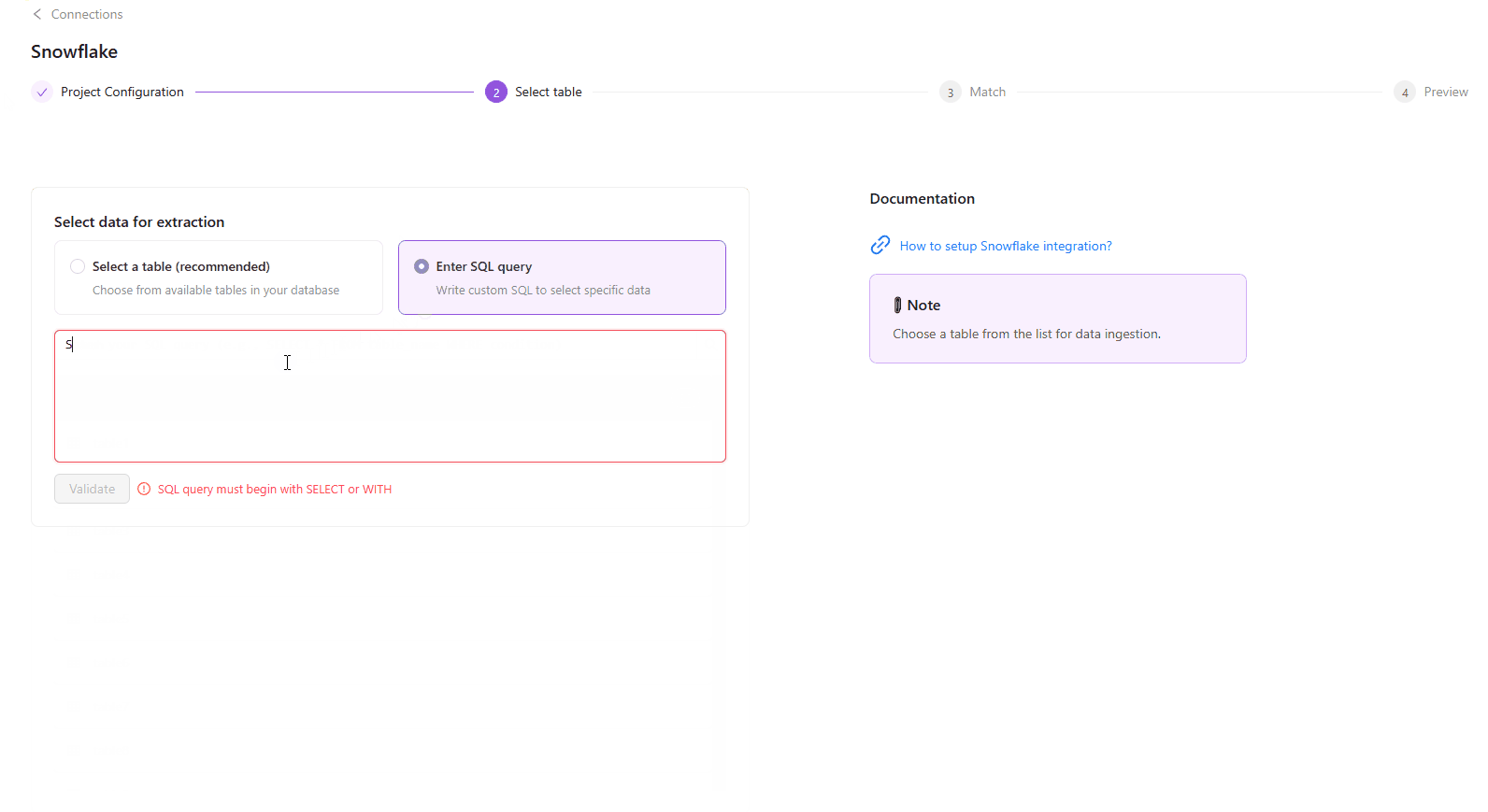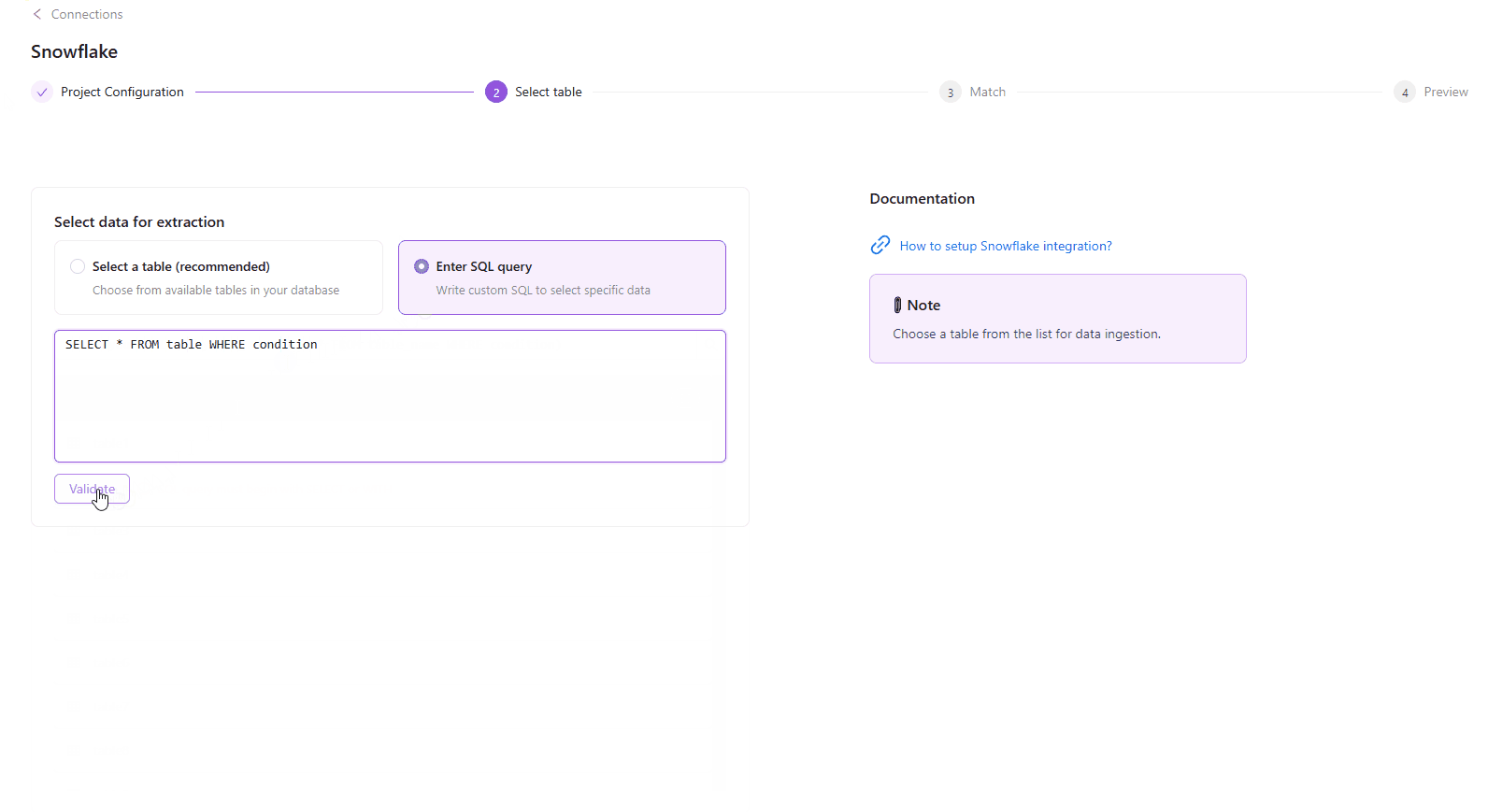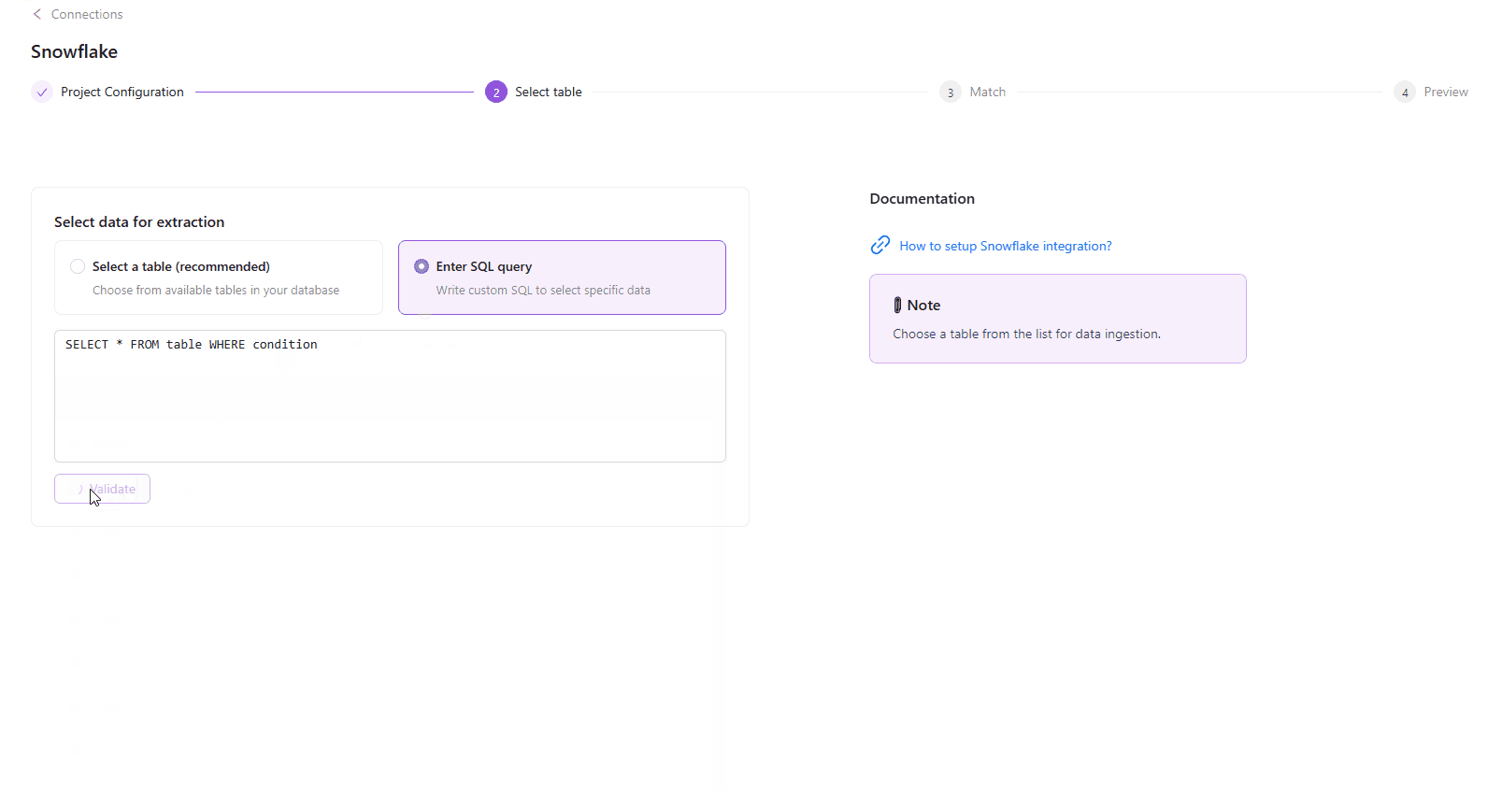
Select the SQL query option, while setting up your flat data extraction.
Enter custom SQL in the field.
Click the Validate button to start the SQL query check.
Click on the Continue button.
Below are common use cases and best practices for using custom SQL effectively.
Cross-Project Queries
You can use the Custom SQL query feature to extract data via cross-project queries directly, without going through GBQ manually. This enables you to pull data from another project or dataset seamlessly.
Enter your GBQ project ID:your-project-id and any dataset name in this project, e.g.: your-dataset.
Select the Enter SQL query option and enter the query to fetch data from a different project.
Example:
SELECT *
FROM other-project.dataset.view_name;
Use cases:
- Access data stored in a separate GBQ project without needing direct GBQ access.
- Simplify cross-project reporting workflows.
Time-Based Table Patterns
Many data warehouses store time-partitioned tables with naming conventions like events_2024_10 or orders_2025_01.
Custom SQL lets you query these tables dynamically using wildcards or pattern matching.
Example:
SELECT *
FROM events_2024*
WHERE event_type = 'purchase';
Use cases:
- Combine data from multiple time-based partitions (e.g., all months in 2024).
- Automate queries without manually listing each table.
Pre-Aggregation in SQL
Instead of pulling raw event-level data, you can aggregate metrics directly in SQL to reduce data volume and improve performance.
Example:
SELECT *
FROM events_2024*
WHERE event_type = 'purchase';
Use cases:
- Summarize metrics by campaign, region, or channel before loading data into a report or dashboard.
- Optimize query cost and processing time.
Creating Calculated Fields Directly in SQL
You can derive new metrics or KPIs using SQL expressions. This allows you to add calculated fields that don’t exist in the source schema.
Example:
SELECT
campaign_id,
(cost / impressions) * 1000 AS CPM,
(revenue - cost) / cost AS ROI
FROM campaign_stats;
Use cases:
- Create dynamic business metrics (e.g., CPM, CTR, ROI) directly in the query layer.
- Simplify downstream data transformations.
Filtering Large Datasets Before Extraction
To reduce data load and processing time, apply filters directly in SQL. This ensures that only the most relevant subset of data is extracted.
Example:
SELECT *
FROM events
WHERE date >= CURRENT_DATE - INTERVAL '30 days'
AND campaign_status = 'active';
Use cases:
- Load only the most recent records (e.g., last 30 days).
- Exclude inactive or irrelevant entities before data transformation.
Selecting from CTEs (Common Table Expressions)
CTEs allow you to structure complex queries for readability and modularity. They’re especially useful when multiple intermediate steps are needed.
Example:
WITH active AS (
SELECT *
FROM users
WHERE status = 'active'
)
SELECT *
FROM active;
Use cases:
- Reuse filtered or transformed datasets within the same query.
- Improve maintainability and clarity for multi-step logic.
Was this article helpful?
Thanks for the feedback!