Product Overview
Key differentiators
- Improvado Attribution operates on top of a Data Warehouse (DWH), eliminating the need for setting up a dedicated pixel tracking tool, as is often required by our competitors.
- Suitable for companies with a complex tech stack (e.g., 3 CRM, 5 payment platforms, 2 eCommerce).
- Our service supports over 300 data sources for attribution, thanks to Improvado's capacity as an Extract, Transform, Load (ETL) platform.
- Our attribution product is designed with customization in mind, offering flexibility in data preparation, the addition of any sources, and mapping.
- With our Professional Service, you can customize and adjust the Attribution for your needs.
Attribution Core Schema
Attribution Core is a part of Marketing Attribution Platform and includes the following stages of data processing:
- Union
- Goals Initialization
- Attribution Models Calculation
You can see the data flow in Marketing Attribution Platform in the diagram below:
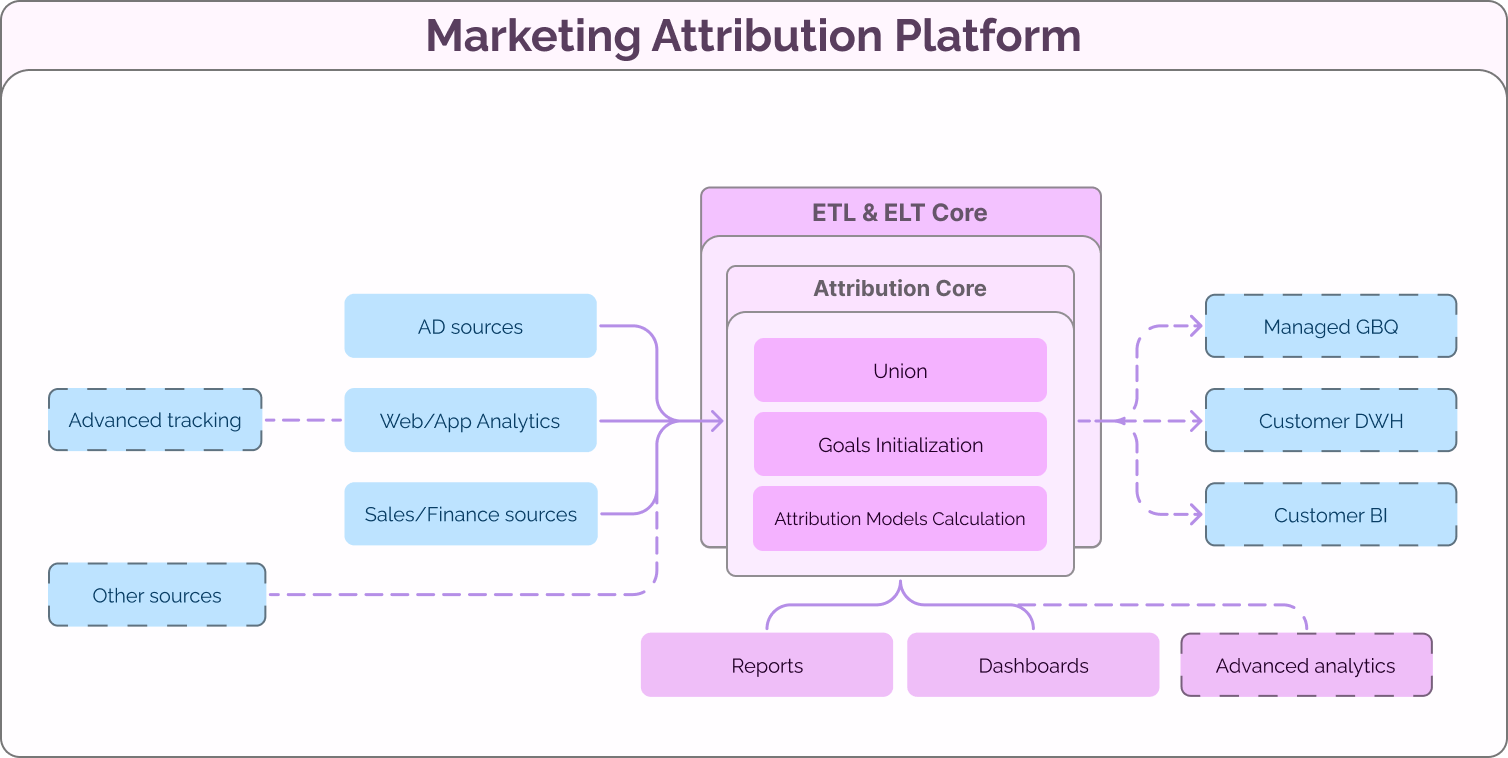
General Overview of the Attribution Core Logic
- We combine data from different sources using our Marketing Common Data Model and build it into a chain of events.
- We then apply our identity resolution engine based on the ID Graph, which finds direct and indirect relationships in sources at the User ID and PII levels.
- The found relationships are assigned unique IDs at the user and company levels. The resulting IDs are used for Multi-Touch Attribution Models.
- For each model, conversion or transactional goals are defined, a lookback window is set, and the type of attribution is at the user level (B2C) or account-based (B2B). For each global user id or global account id, the events associated with the target are combined into macro sessions.
- As a result, the output is a summary table with the calculated weights of each touch and the associated marketing channel down to the keyword in close relation to the user or account identifiers.
Improvado Attribution uses Activity Streams (hit-level data), so the input has to have a certain level of granularity. E.g., Google Analytics reports won’t work since they provide more high-level data than required, so we pull hit-level data instead.
Data Preparation
The data preparation stage is essential for transforming raw data into a structured format, ready for analysis. Key steps include:
- Data Deduplication: Identifying and removing duplicate records for accuracy.
- Data Normalization: Standardizing values, units, and formats across data sources.
- Data Transformation: Converting complex structures into flat table format.
- Data Extraction: Retrieving specific information, such as UTM parameters from URLs.
In particular, mandatory fields used in the core are simplified as follows:
- timestamps in datetime format;
- event names as lowercase strings;
- event IDs formatted as strings.
These operations result in flat tables containing all relevant fields, serving as the data source for the attribution core and for preparing final tables with a complete set of fields from all sources.
The Identity Graph (ID Graph)
Improvado Attribution approaches The Identity Graph for determining the relations between the data from the different sources.
The Identity Graph connects and unifies data from multiple sources such as Salesforce, Chili Piper, Mixpanel, Hubspot, and GA4, etc. The process includes the following steps:
- Prepare Dictionaries in Staging: Create dictionaries for each data source containing key relations, such as email, user IDs, and other identifiers.
- Salesforce:
email,google_clientid,contact_id,account_id,opportunity_id - Chili Piper:
email,event_id - Mixpanel:
email,distinct_id - Hubspot:
email,google_client_id,contact_id,company_id,deal_id - GA:
google_client_id - Identity Resolution: Match and link records based on common identifiers from data source dictionaries, creating a unified view of each user with interactions and data points from all platforms.
- Generate Unique IDs: Create unique global_account_id and global_user_id based on the unified view using CityHash64.
- Prepare Single Dataset: Merge unified user data and generated IDs into a single dataset, combining keys from all sources and unique generated IDs.
- Reverse Joining: Link global_ids back to Staging tables for use it in future core transformations
Was this article helpful?
Thanks for the feedback!